

Preface ⚡
This blog is dedicated to sharing the key insights and lessons I have acquired from my experience with MediaPipe.
It specifically highlights the advancements brought by the new Solutions suite & Tasks API (Vision). To gain a comprehensive understanding of the subject, I strongly recommend referring to MediaPipe’s official documentation, available 🔗 here.
Join me on my Google Summer of Code 2023 journey as I utilize MediaPipe to create interactive web demos. Stay tuned for exciting blog posts with experiments and valuable insights.
🔺 A few important links to get you started:
For more information about the project, please visit here: Interactive Web Demos using the MediaPipe Machine Learning Library.
Explore my Community Bonding experience here: Community Bonding Period Experience.
Explore what’s next here: Predicting Custom Gestures.
Many Machine Learning applications in various domains heavily depend on fundamental baseline tasks. For instance, applications involving gestural navigation or sign language detection require accurate hand tracking capabilities. However, developing a reliable hand tracking model can be a time-consuming and resource-intensive process, leading to a bottleneck in the creation of such applications. In order to overcome this challenge, Google has developed a solution called MediaPipe, which aims to streamline the development of applications that rely on hand tracking.
Introduction to MediaPipe 🦄
MediaPipe is a cross-platform pipeline framework to build custom machine learning solutions for live and streaming media & was open-sourced by Google.
💡 MediaPipe offers essential Machine Learning models for prevalent tasks such as hand tracking. By providing these models, MediaPipe effectively eliminates the development bottleneck faced by numerous Machine Learning applications. The inclusion of user-friendly APIs further simplifies the development process and reduces the overall project timeline for applications relying on Computer Vision. The official documentation states that inferencing is real-time, and it takes just a few lines of code to create a perception pipeline.
What is MediaPipe used for? 🤔
MediaPipe is a primarily used for building real-time multimedia processing pipelines. It provides tools, libraries, and pre-built components for tasks like video analysis, object detection, facial recognition, and gesture recognition, etc. MediaPipe enables efficient processing and analysis of media streams, making it ideal for applications in augmented reality, virtual reality, robotics, and machine learning. It also supports rapid prototyping of perception pipelines with AI models and facilitates deployment on various hardware platforms.
The configuration language and evaluation tools enable teams to incrementally improve computer vision pipelines.

Who can use MediaPipe ?
MediaPipe can be used by a wide range of users, including developers, researchers, and engineers. It is designed to be accessible to individuals and teams working on various projects involving multimedia processing, computer vision, machine learning, and AI. Whether you are creating applications, conducting experiments, or building innovative solutions, MediaPipe provides a flexible platform for implementing and deploying your ideas.
What are the advantages of MediaPipe ?
- Easy to use: Self-serve ML solutions with simple-to-use abstractions. Use low-code APIs or no-code studio to customize, evaluate, prototype, and deploy.
- Innovative: Advanced ML solutions for popular tasks, crafted with Google ML expertise.
- End-to-end acceleration: Use common hardware to build-in fast ML inference and video processing, including both CPU & GPU.
- Lightweight: The framework is designed to run on mobile and edge devices with limited compute resources.
- Cross-Platform: Build once, deploy anywhere! The unified framework is suitable for Web, Android, iOS, desktop, edge, cloud, and IoT platforms.
- Ready-to-use: Prebuilt ML solutions demonstrate the full power of the MediaPipe framework.
- Open source and free: The framework is licensed under Apache 2.0, fully extensible, and customizable.
A brief history of MediaPipe 📜
MediaPipe powers the ML in many Google products, and it’s open source to help you to bring cutting-edge, performant, and scalable features to your customers. Since 2012, Google has used it internally in several products and services. It was initially developed for real-time analysis of video and audio on YouTube. Gradually it got integrated into many more products, the following are some:
- Google Meet 👪
- Object detection in Google Lens 👁️
- Google Photos 🖼️
- Google Home 🏠
- Perception system in NestCam 📹
🟢 MediaPipe is the driving force behind groundbreaking products and services that we rely on in our daily lives. In contrast to resource-intensive machine learning frameworks, MediaPipe operates with minimal resource requirements. Its compact and efficient design allows it to be deployed even on low-powered embedded IoT devices.
MediaPipe Toolkit 🧰
The Toolkit comprises the Framework and the Solutions. The following diagram shows the components of the MediaPipe Toolkit.
MediaPipe Framework
🟣 MediaPipe Framework consists of three main elements:
- A framework for inference from sensory data (audio or video)
- A set of tools for performance evaluation and visualization
- Re-usable components for inference and processing (calculators)
🔵 The main components of MediaPipe:
Packet: The basic data flow unit is called a “packet”. It consists of a numeric timestamp and a shared pointer to an immutable payload.
Graph: Processing takes place inside a graph which defines the flow paths of packets between nodes. A graph can have any number of input and outputs, and branch or merge data.
Nodes: Nodes are where the bulk of the graph’s work takes place. They are also called “calculators” (for historical reasons) and produce or consume packets. Each node’s interface defines a number of in- and output ports.
Streams: A stream is a connection between two nodes in real-time that carries a sequence of packets with increasing timestamps.
There are more advanced components, such as Side packets, Packet ports, Input policies, etc., about which you can read more 🔗 here. To visualize a graph, copy and paste the graph into the MediaPipe Visualizer.
Graphs
The MediaPipe perception pipeline is called a Graph. Let us take the example of the first solution, Hands. We feed a stream of images as input which comes out with hand landmarks rendered on the images.
The flow chart below represents the MediaPipe hand solution graph.
🛈 In computer science jargon, a graph consists of Nodes connected by Edges. Inside the MediaPipe Graph, the nodes are called Calculators, and the edges are called Streams. Every stream carries a sequence of Packets that have ascending time stamps. In the image above, we have represented Calculators with rectangular blocks and Streams using arrows (→).
Calculators
These are specific computation units with assigned tasks to process. The packets of data (Video frame or Audio segment) enter and leave through the ports in a calculator. When initializing a calculator, it declares the packet payload type that will traverse the port. Every time a graph runs, the Framework implements Open, Process, and Close methods in the calculators. Open initiates the calculator; the process repeatedly runs when a packet enters. The process is closed after an entire graph run.
ⓘ As an example, consider the first calculator shown in the above graph. The calculator, ImageTransform, takes an image at the input port and returns a transformed image in the output port. On the other hand, the second calculator, ImageToTensor, takes an image as input and outputs a tensor.
Calculator Types in MediaPipe
All the calculators shown above are built-in into MediaPipe. We can group them into four categories.
Pre-processing calculators are a family of image and media-processing calculators. The ImageTransform and ImageToTensors in the graph above fall in this category.
Inference calculators allow native integration with Tensorflow and Tensorflow Lite for ML inference.
Post-processing calculators perform ML post-processing tasks such as detection, segmentation, and classification. TensorToLandmark is a post-processing calculator.
Utility calculators are a family of calculators performing final tasks such as image annotation.
The calculator APIs allow you to write your custom calculator.
MediaPipe Solutions 🧩
MediaPipe Solutions is a versatile framework based on MediaPipe for creating machine learning pipelines across platforms. It offers customizable building blocks for applying AI and ML techniques to your specific requirements. With MediaPipe Solutions, you can quickly integrate and customize these solutions in your applications, supporting multiple development platforms. It is available for Web (JavaScript), Python, and Android (Java), and is part of the open-source MediaPipe project, allowing further customization as needed.
These libraries and resources provide the core functionality for each MediaPipe Solution:
- MediaPipe Tasks: Cross-platform APIs and libraries for deploying solutions. Learn more.
- MediaPipe Models: Pre-trained, ready-to-run models for use with each solution.
These tools let you customize and evaluate solutions:
- MediaPipe Model Maker: Customize models for solutions with your data. Learn more.
- MediaPipe Studio: Visualize, evaluate, and benchmark solutions in your browser. Learn more.
For our project, we will utilize Hand Landmark Detection and Gesture Recognition. Furthermore, we will customize the Gesture Recognition Model using MediaPipe Model Maker and incorporate the task-vision package from MediaPipe which I’ll be covering in another blog which can be accessed 🔗 here.
○ Notable Tasks-Vision package Classes:
| Class | Description |
| DrawingUtils | Helper class to visualize the result of a MediaPipe Vision task. |
| FilesetResolver | Resolves the files required for the MediaPipe Task APIs. |
| GestureRecognizer | Performs hand gesture recognition on images. |
| HandLandmarker | Performs hand landmarks detection on images. |
○ Notable Tasks-Vision package Interfaces:
| Interfaces | Description |
| BoundingBox | An integer bounding box, axis aligned. |
| Category | A classification category. |
| Classifications | Classification results for a given classifier head. |
| Detection | Represents one detection by a detection task. |
| DetectionResult | Detection results of a model. |
| DrawingOptions | Options for customizing the drawing routines. |
| Embedding | List of embeddings with an optional timestamp. |
| GestureRecognizerOptions | Options to configure the MediaPipe Gesture Recognizer Task. |
| GestureRecognizerResult | Represents the gesture recognition results generated by GestureRecognizer. |
| HandLandmarkerOptions | Options to configure the MediaPipe HandLandmarker Task. |
| HandLandmarkerResult | Represents the hand landmarks detection results generated by HandLandmarker. |
| Landmark | Landmark represents a point in 3D space with x, y, z coordinates. |
| LandmarkData | Data that a user can use to specialize drawing options. |
| NormalizedLandmark | Represents a point in 3D space with x, y, z coordinates. |
| RegionOfInterest | A Region-Of-Interest (ROI) to represent a region within an image. |
○ Notable Tasks-Vision package Type Aliases:
| Type Aliases | Description |
| Callback | A user-defined callback to take input data and map it to a custom output value. |
| ImageSource | Valid types of image sources which we can run our GraphRunner over. |
| PoseLandmarkerCallback | A callback that receives the result from the pose detector. |
The introduction of MediaPipe Solutions brought forth a fresh set of on-device machine learning tools aimed at simplifying the developer workflow. MediaPipe Solutions provides a suite of libraries and tools for you to quickly apply artificial intelligence (AI) and machine learning (ML) techniques in your applications. You can plug 🔌 these solutions into your applications immediately, customize 🛠️ them to your needs, and use 👨💻 them across multiple development platforms. These offer convenient solutions, ranging from no-code to low-code options, for common on-device machine learning tasks for platforms like Web, Mobile, Desktop, and IoT.
MediaPipe Tasks API 📝
MediaPipe Tasks simplifies on-device machine learning deployment for Web, Mobile, IoT, and Desktop developers through low-code libraries. By utilizing these libraries, developers can easily incorporate on-device machine learning solutions, as demonstrated in the aforementioned examples, into their applications with just a few lines of code. This approach eliminates the need to acquire extensive knowledge of the implementation details behind these solutions. Currently, MediaPipe Tasks offers tools across three categories: vision, audio, and text, catering to a wide range of application requirements.
The impact of the Mediapipe Tasks API in real-world projects has been remarkable. Here are the key takeaways:
Versatile and User-Friendly: The Tasks API provides developers with a versatile and easy-to-use tool for integrating Machine Learning (ML) models into their projects. With its pre-trained models, comprehensive APIs, and data processing tools, developers can efficiently leverage ML without extensive expertise in model architecture.
Solving Real-World Problems: Through the development of these projects using the Tasks API, the power of ML across various domains becomes evident. From object detection in images to audio classification and sentiment analysis, it has proven its value in automating various tasks.
Harnessing Pre-trained Models: Pre-trained models play a vital role in ML-powered projects, serving as a valuable starting point for training and saving time and resources compared to training models from scratch. The Tasks API offers a repository of pre-trained models that can be readily employed for different tasks.
Seamless Integration: Integrating Mediapipe with other tools and APIs is a seamless process, allowing developers to combine its capabilities with other frameworks and solutions effortlessly.
The MediaPipeTasks API offers developers an array of opportunities to harness the capabilities of Machine Learning in their projects. It simplifies the integration of Machine Learning with its user-friendly interface, adaptability, and availability of pre-trained models. Moreover, MediaPipe Tasks ensures consistency across various platforms, regardless of the specific task at hand. This advantage allows faster development by enabling the reuse of the same logic across different applications.
📅 In December 2022, Google introduced the MediaPipe preview (currently in early release), featuring five tasks:
• Gesture Recognition, which lets you recognize hand gestures in real time, and provides the recognized hand gesture results along with the landmarks of the detected hands from an image or video. You can use this task to recognize specific hand gestures from a user, and invoke application features that correspond to those gestures.
• Hand Landmarker, which lets you detect the landmarks of the hands in an image or video. You can use this Task to localize key points of the hands and render visual effects over the hands.
• Image Classification, which lets you perform classification of multiple classes of objects within an image or video. You can use this task to identify what an image represents among a set of categories defined at training time.
• Object Detection, which lets you detect the presence and location of multiple classes of objects within images or videos. For example, an object detector can locate dogs within in an image or video.
• Text Classification, which lets you classify text into a set of defined categories, such as positive or negative sentiment. The categories are defined during the training of the model.
🛑 MediaPipe Solutions are available across multiple platforms. Each solution includes one or more models, and you can customize models for some solutions as well. The following list shows what solutions are available for each supported platform and if you can use MediaPipe Model Maker to customize the model:
🛈 You can access the entire list of available solutions here & its corresponding GitHub repository here.
💡 Building upon this initial release, Google I/O 2023 showcased the announcement of nine new tasks, some of them include:
• Face Landmarker, which detects facial landmarks and blendshapes to determine human facial expressions, such as smiling, raised eyebrows, and blinking. Additionally, this task is useful for applying effects to a face in three dimensions that matches the user’s actions.

• Image Segmenter, which lets you divide images into regions based on predefined categories. You can use this functionality to identify humans or multiple objects, then apply visual effects like background blurring.

• Interactive Segmenter, which takes the region of interest in an image, estimates the boundaries of an object at that location, and returns the segmentation for the object as image data.

📅 On 29th June 2023, MediaPipe launched Image Generator, which enables developers to apply a diffusion model within their apps to create visual content.
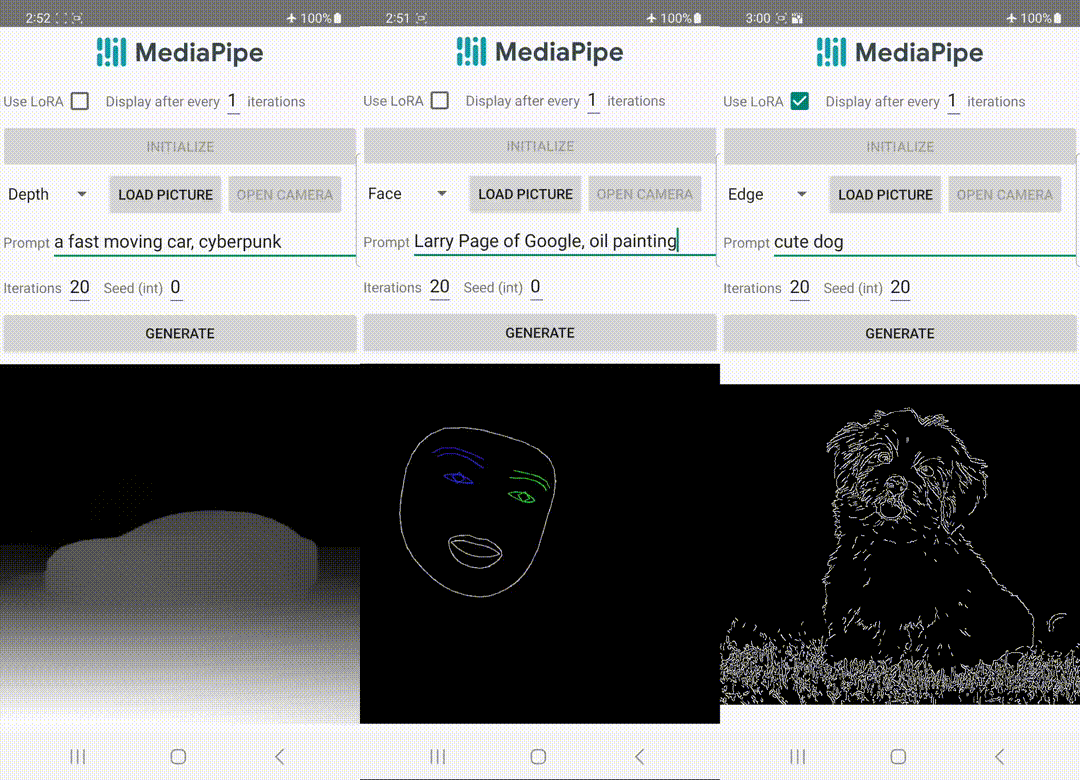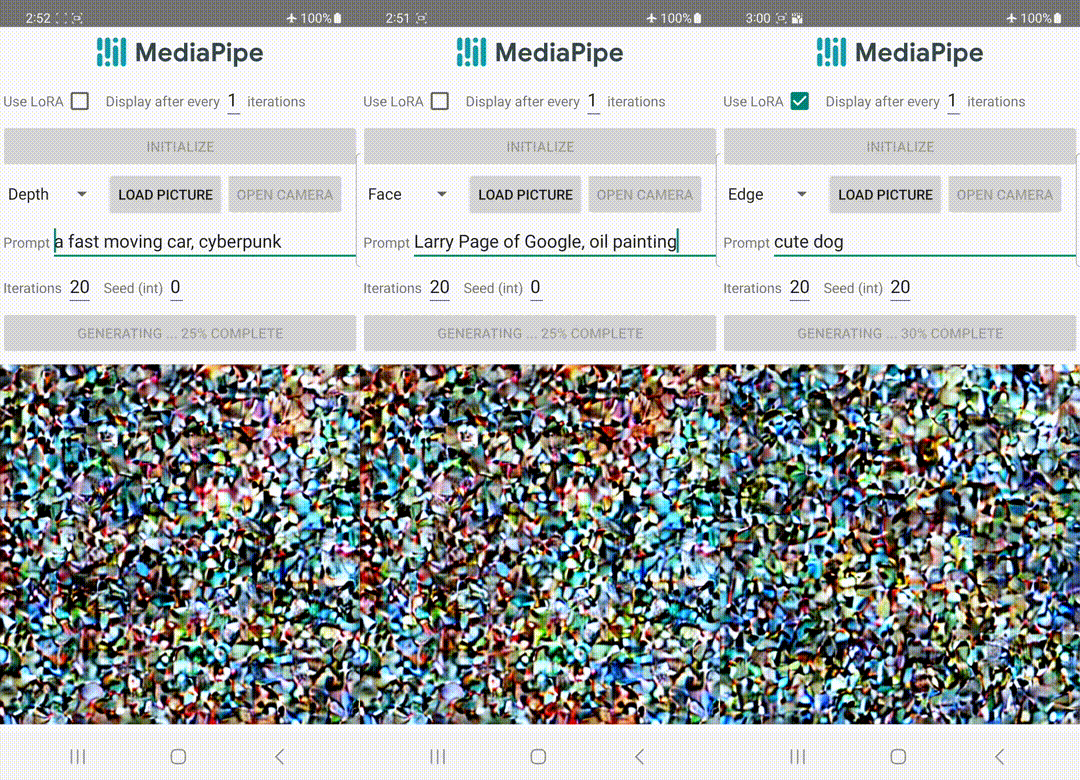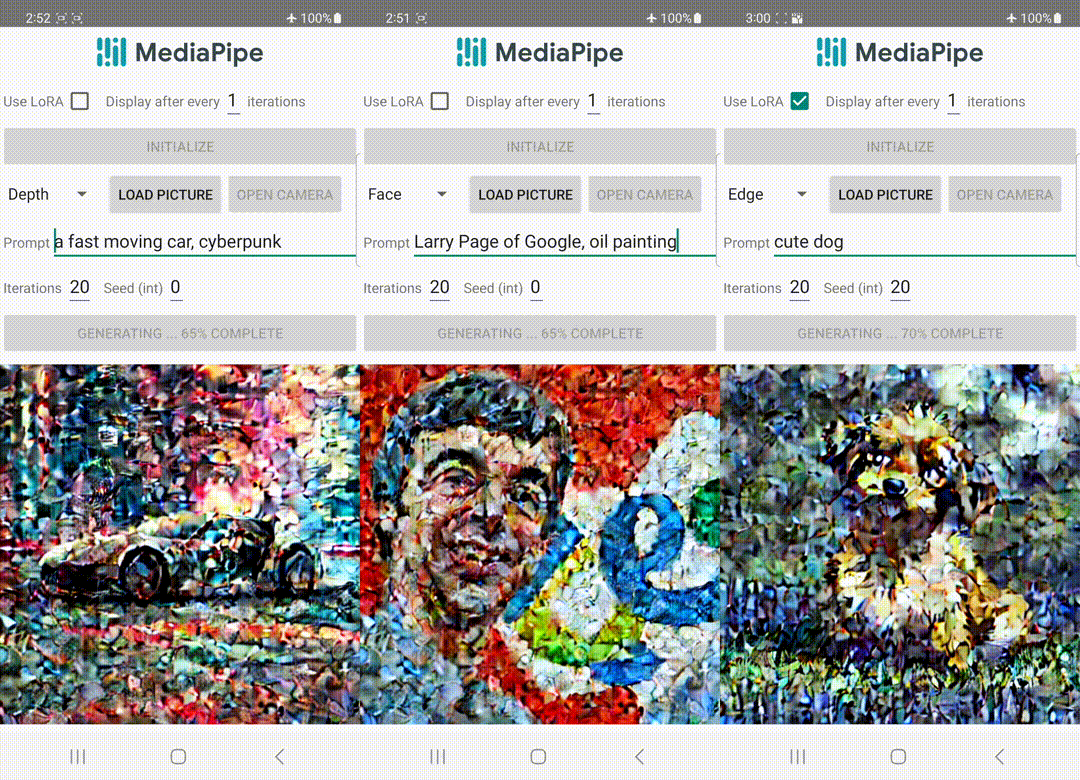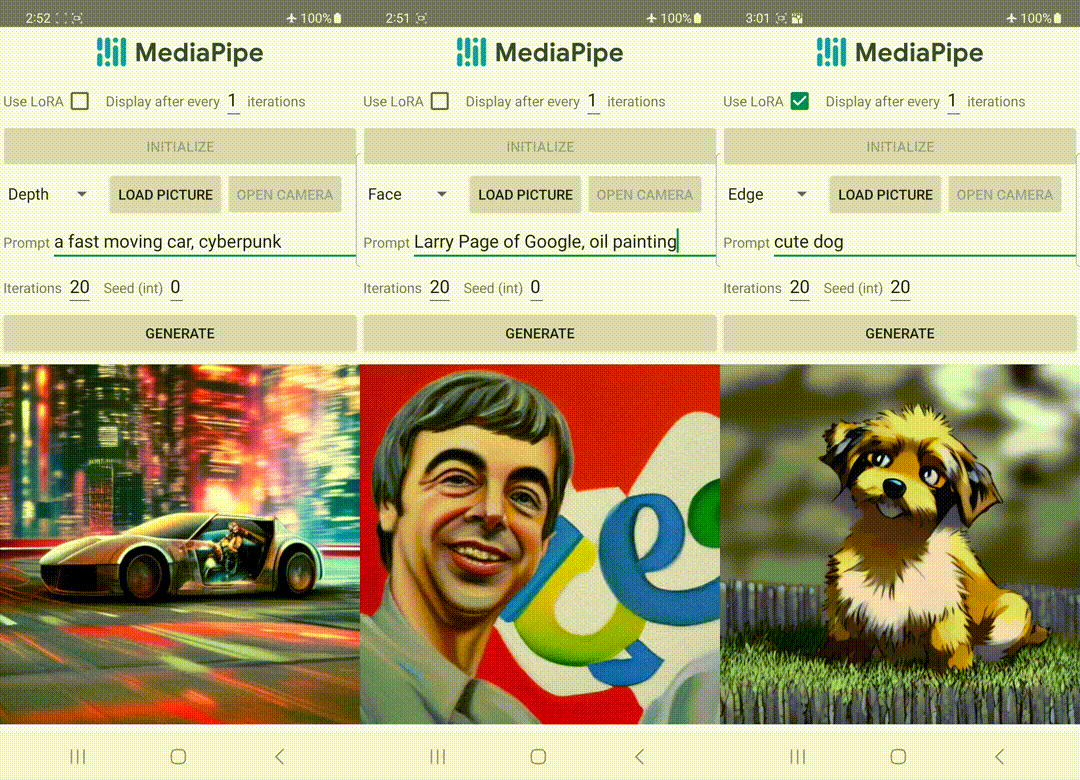
🛈 Feel free to explore the blog on On-device diffusion plugins for conditioned text-to-image generation by Google AI which sheds more light on the diffusion models and how they work.
Soon, they’re also planning to bring Face Stylizer, which lets you take an existing style reference and apply it to a user’s face using “style transfer” method.
The MediaPipe Tasks Web JavaScript API is divided into packages that perform ML tasks in major domains, including vision, natural language, and audio. The following is a list of script imports you can add to your Web and JavaScript development project to enable these APIs:
1<head>23 <!-- For tasks-vision -->4 <script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-vision/vision_bundle.js"5 crossorigin="anonymous"></script>67 <!-- For tasks-text -->8 <script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-text/text-bundle.js"9 crossorigin="anonymous"></script>1011 <!-- For tasks-audio -->12 <script src="https://cdn.jsdelivr.net/npm/@mediapipe/tasks-audio/audio_bundle.js"13 crossorigin="anonymous"></script>1415</head>
🛈 Feel free to explore the setup guide for Web 🔗 here.
⚠️ For specific implementation details, see the platform-specific development guides for each solution in MediaPipe Tasks.
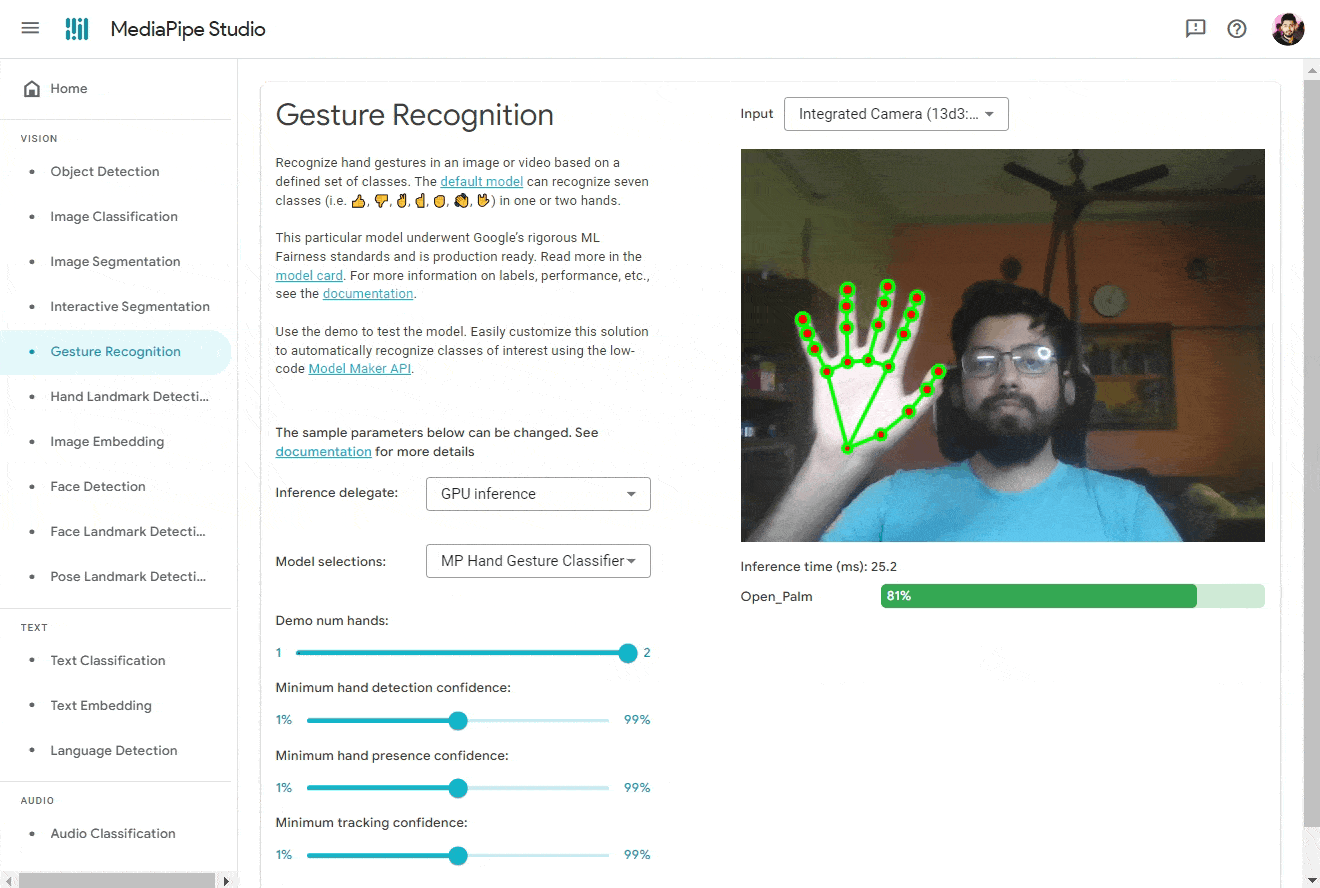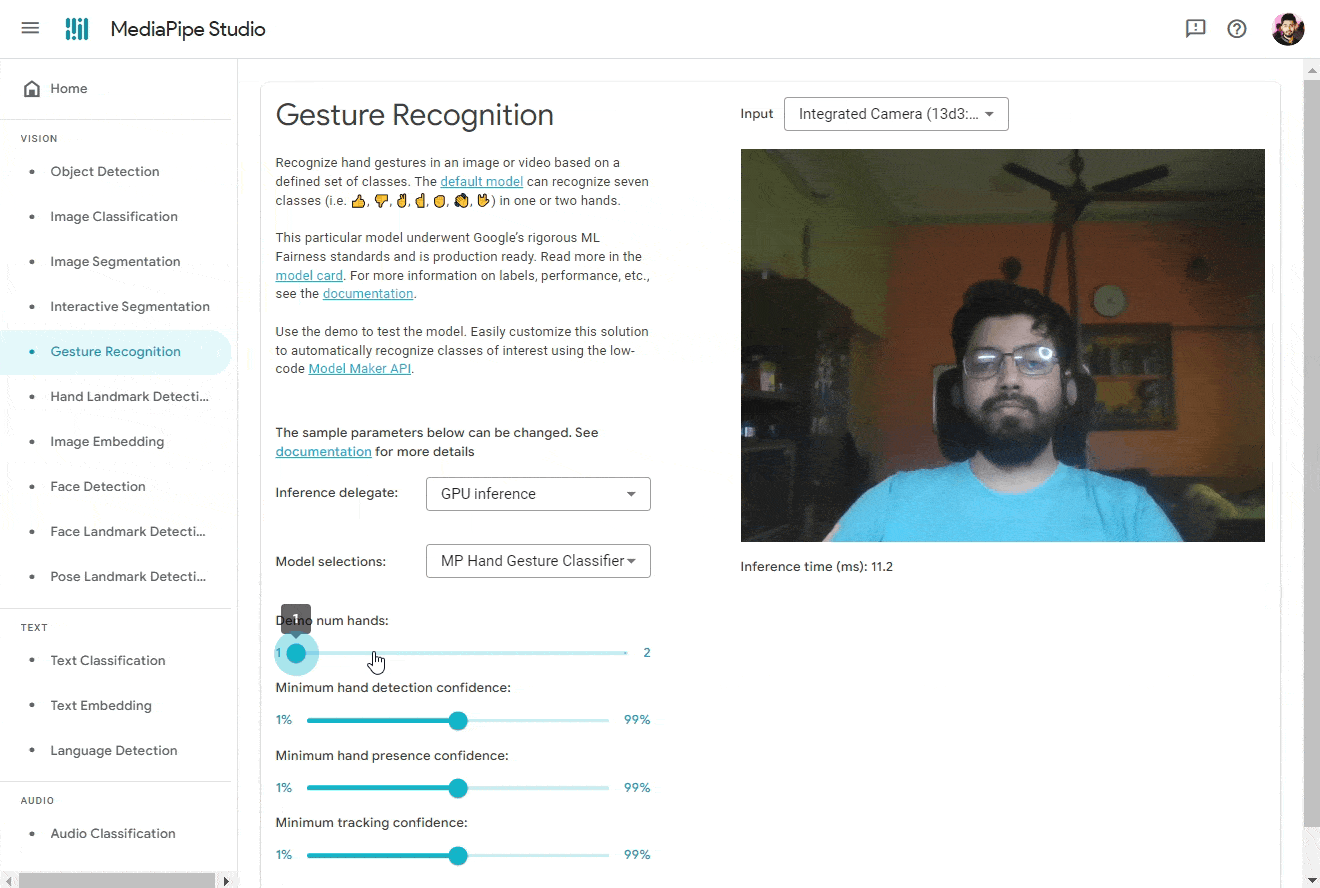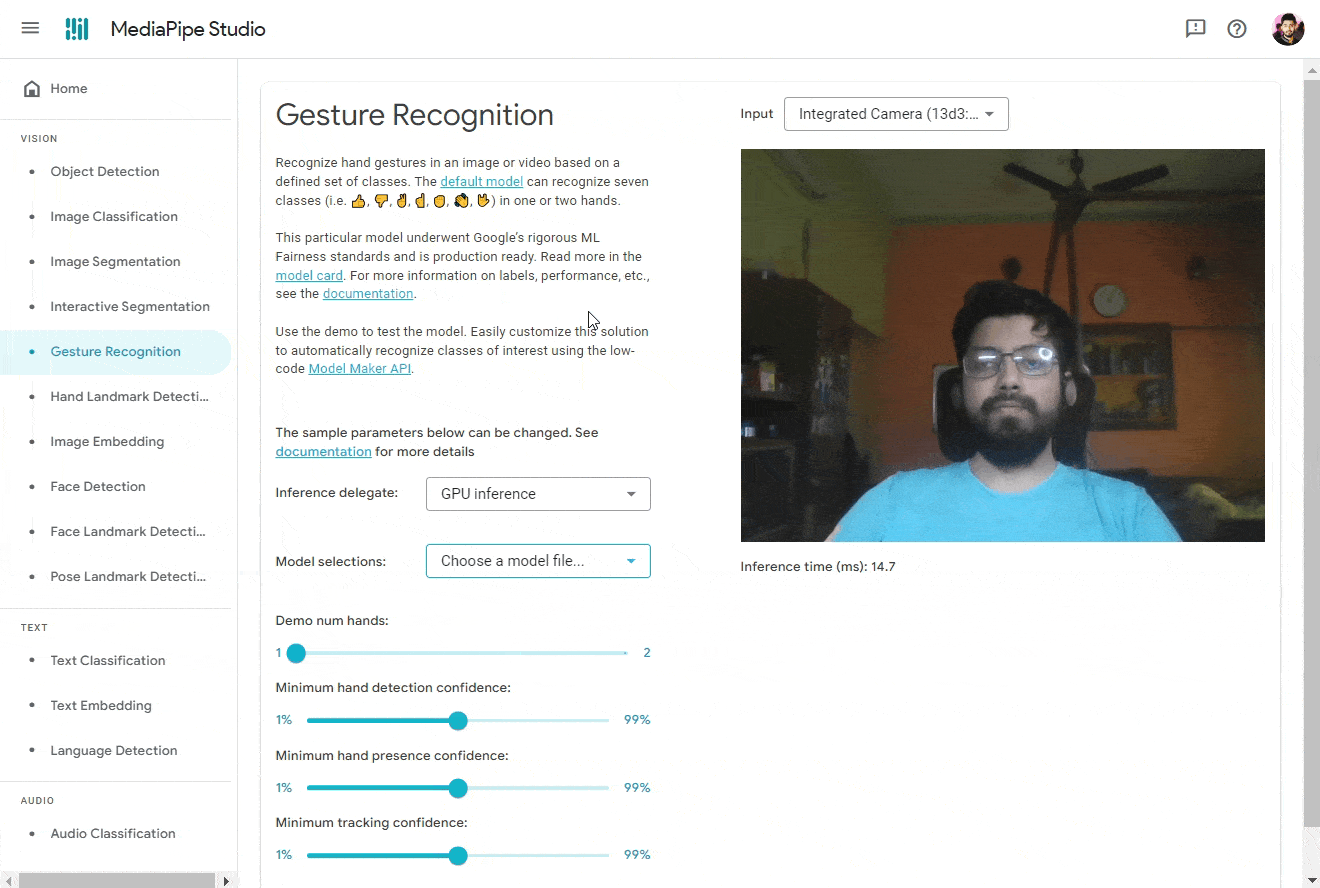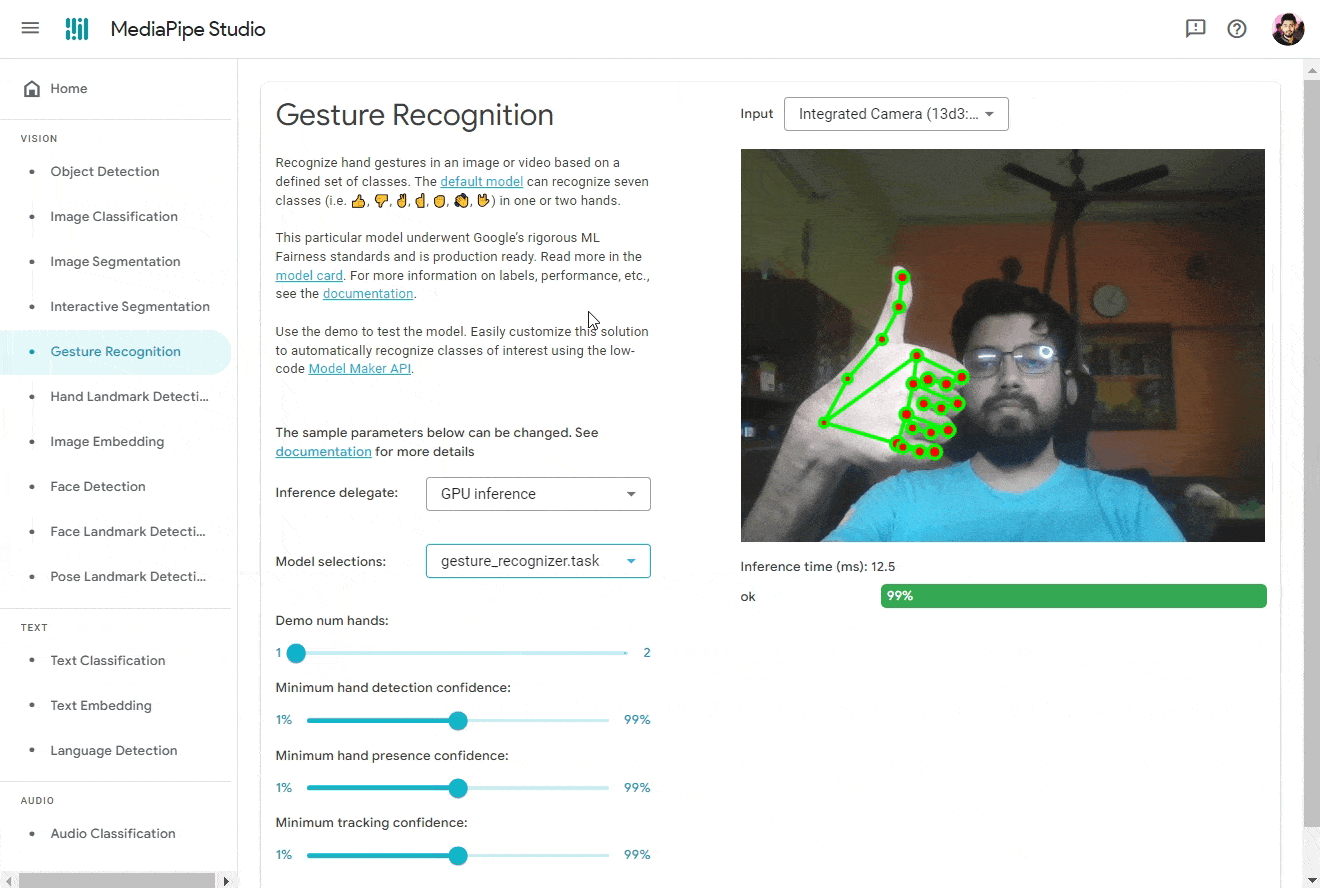
MediaPipe Studio ✨
Introducing MediaPipe Studio, the groundbreaking tool that enables you to conveniently view and test MediaPipe-compatible models directly on the Web 🌐. With MediaPipe Studio, there’s no need to develop custom testing applications.
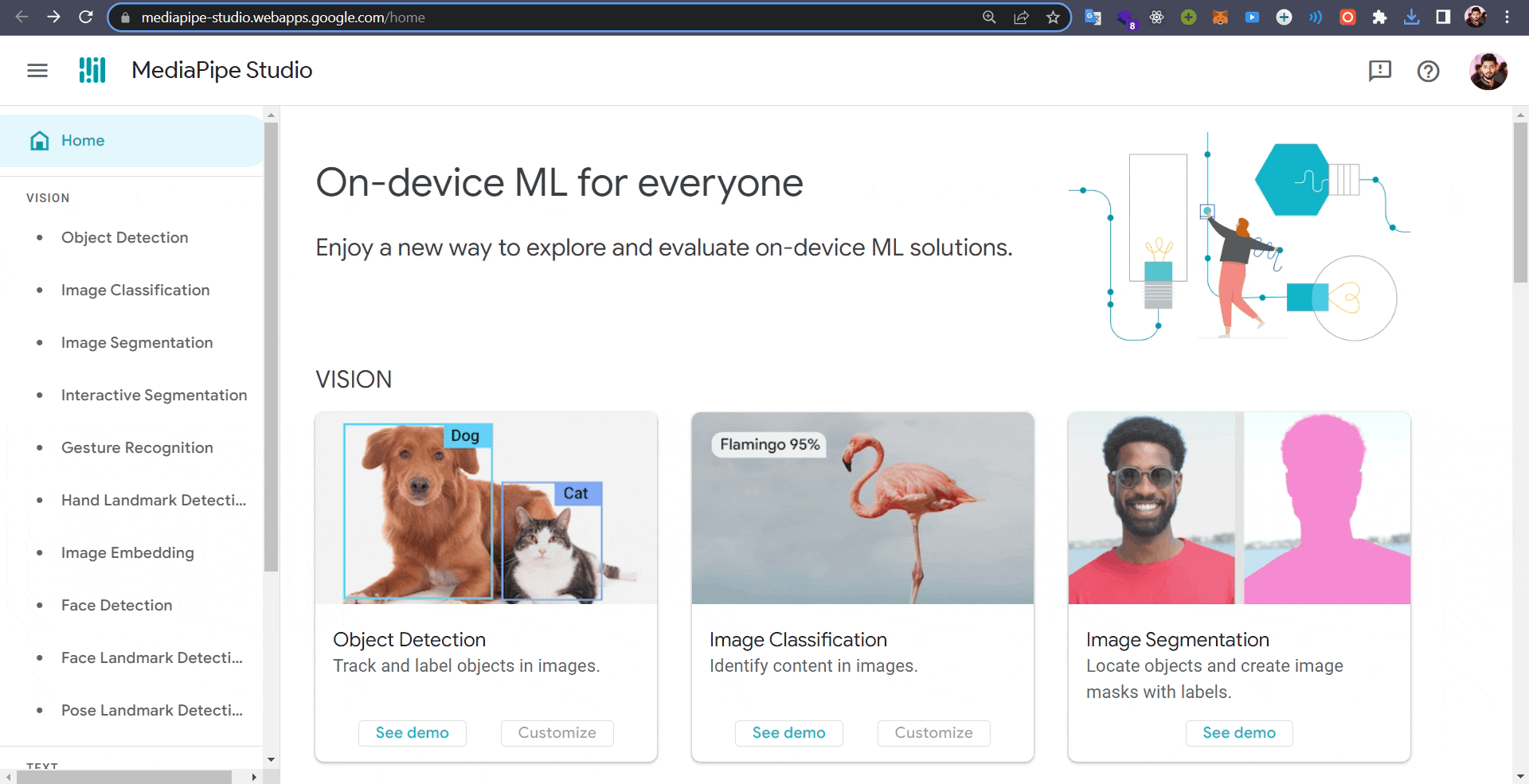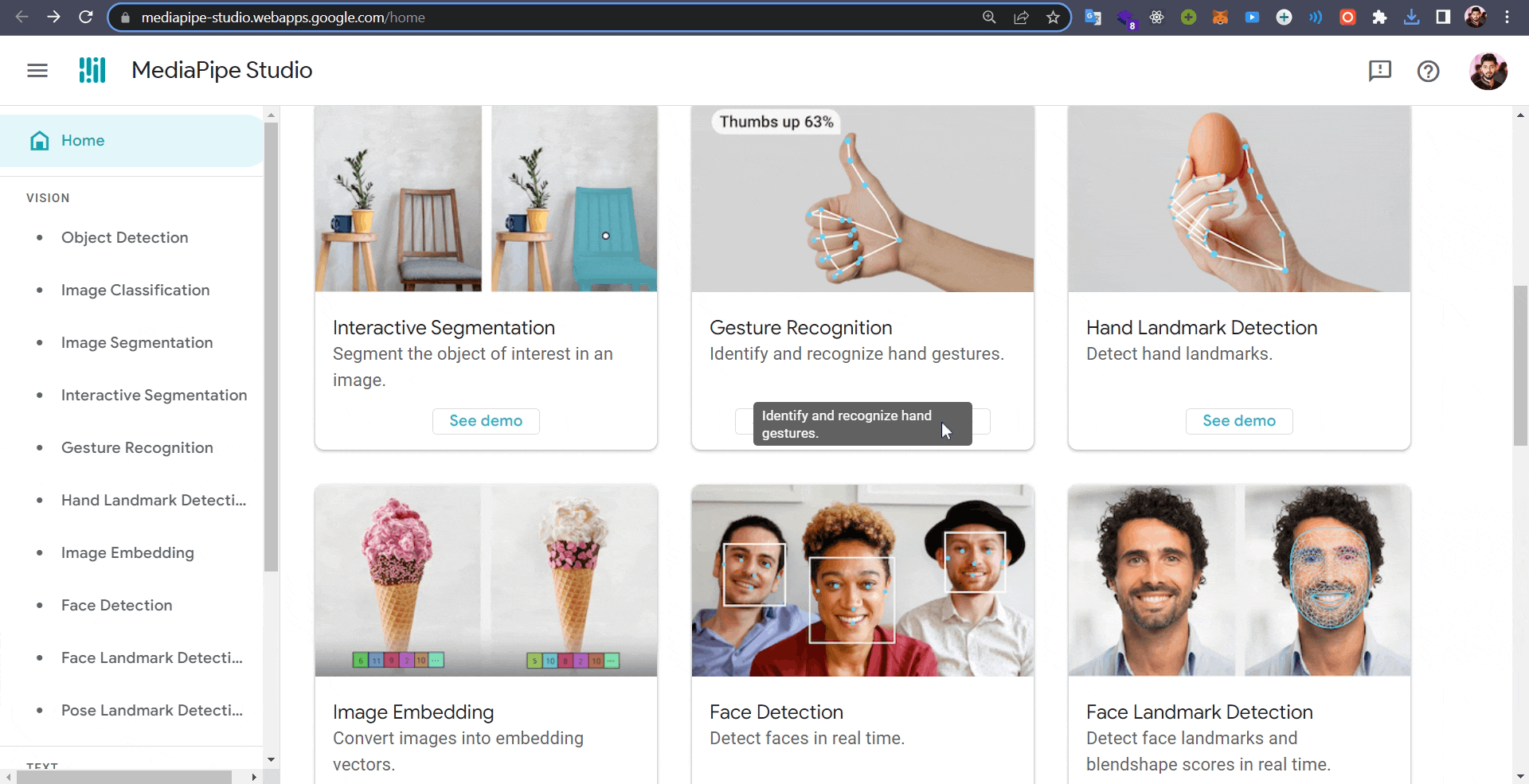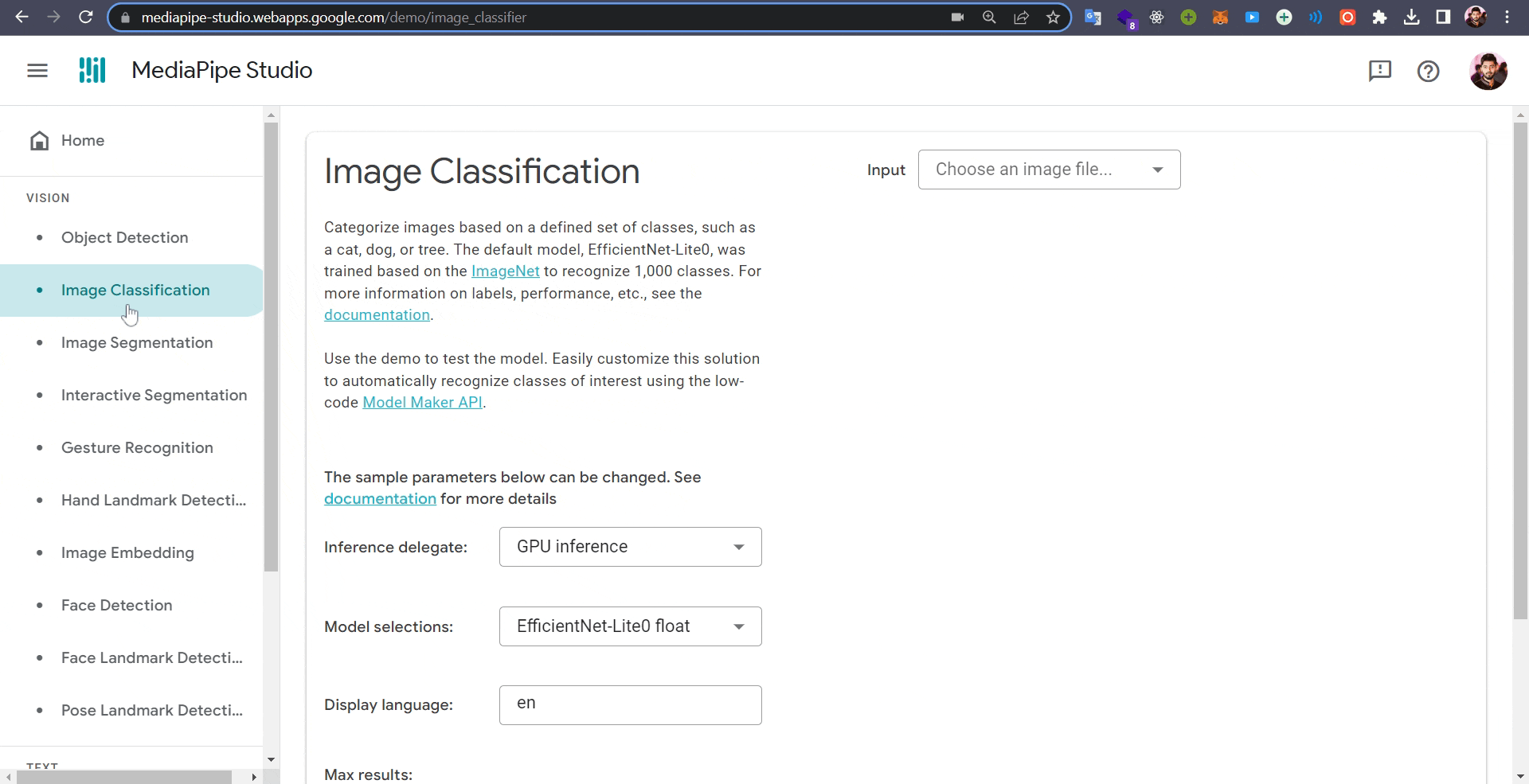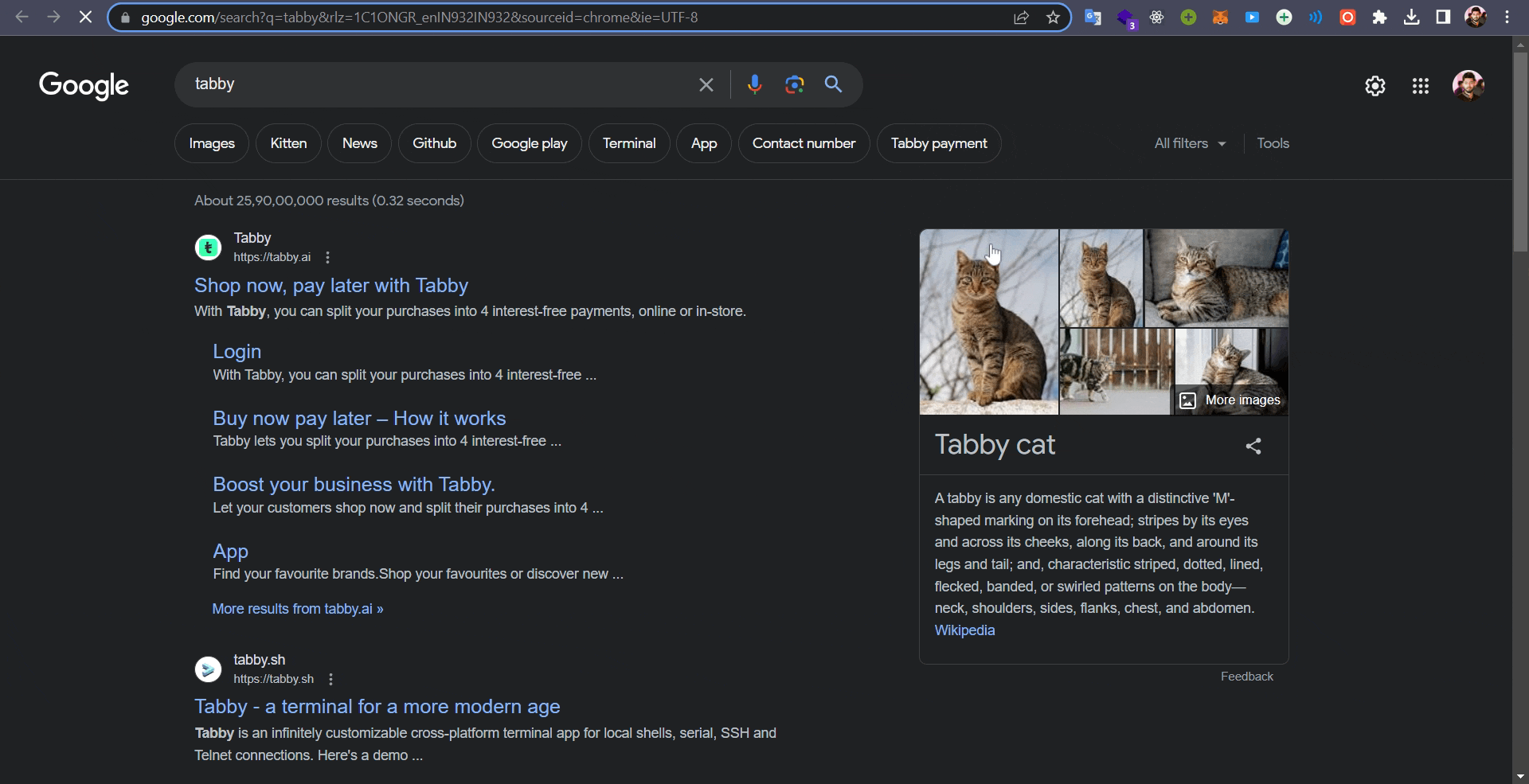
You can explore and experiment with the new tasks mentioned here and other additional features by visiting the MediaPipe Studio page.
🔜 In the future, MediaPipe Studio will also offer a no-code model training solution, allowing you to effortlessly create new models without unnecessary complexities or overhead. Below you can find me using the MediaPipe Studio to to detect hand gestures from my custom trained model.
Visualizer Tool 📊
The MediaPipe Visualizer is a tool for understanding the topology and overall behavior of the pipelines. It provides a timeline view and a graph view. In the timeline view, the user can load a pre-recorded trace file and see the precise timings of data as it moves through threads and calculators (nodes).
In the graph view, the user can visualize the topology of a graph at any point in time, including the state of each calculator and the packets being processed or being held in its input queues. The visualizer can be used to understand the behavior of a pipeline, identify bottlenecks, and debug issues.
🛈 It also provides an easy way to try all the solutions.
In MediaPipe, the protobuf (.pbtxt) text file defines a graph. The MediaPipe Visualizer welcome page greets you with a protobuf file containing a blank graph unit. It has various pre-built graphs of solutions that you can load from the New button at the top right.
The visualizer works within the browser! Let’s give it a try. The following .gif shows an in-browser hand detection example.

Extras:
GPU Support 🏃
MediaPipe supports GPU computing and rendering nodes and allows to combine multiple GPU nodes and mix them with CPU-based nodes. There are several GPU APIs on mobile platforms (OpenGL ES, Metal, Vulkan, etc.)
There is no single cross-API GPU abstraction. Individual nodes can be written using different APIs, allowing them to take advantage of platform-specific features when needed. This enables GPU and CPU nodes to provide advantages of encapsulation and composability while maintaining efficiency.
Tracer Module 👣
The MediaPipe tracer module is responsible for capturing timing events throughout the graph, recording various data fields such as time, packet timestamp, data ID, node ID, and stream ID. It also generates histograms to track different resource metrics, including elapsed CPU time for each calculator and stream.
The tracer module can be activated on demand by configuring it through the GraphConfig settings. Alternatively, the user can exclude the tracer module code entirely using a compiler flag.
💡 By recording timing data, the tracer enables the analysis and visualization of individual packet flows and calculator executions. This data is useful for diagnosing issues such as unexpected real-time delays, memory accumulation caused by packet buffering, and synchronization of packets with varying frame rates.
The aggregated timing data is valuable for reporting average and extreme latencies, facilitating performance tuning. Additionally, the timing data aids in identifying critical path nodes that significantly impact end-to-end latency.
Synchronization and Performance Optimization ⚙️
MediaPipe offers support for multimodal graphs, where different calculators can run concurrently in separate threads to enhance processing speed. To optimize performance, many pre-built calculators provide options for GPU acceleration.
It is crucial to synchronize time series data properly to prevent system disruptions. The graph within MediaPipe ensures that data flow is managed accurately based on packet timestamps. Additionally, the framework takes care of synchronization, context sharing, and inter-operations with CPU calculators.
Dependencies 🏴
MediaPipe depends on OpenCV for video and FFMPEG for audio data handling. It also has other dependencies like OpenGL/Metal, TensorFlow, Eigen, etc.
AI models vs. Applications 🎮
Traditionally, image or video input data is obtained as separate streams and analyzed using neural networks like TensorFlow, PyTorch, CNTK, or MXNet. These models follow a simple and deterministic approach, where each input generates a single output, enabling efficient processing. For a detailed comparison between TensorFlow and PyTorch, you can check out this 🔗 blog.
In contrast, MediaPipe operates at a higher-level semantic, enabling more intricate and dynamic behaviors. For instance, a single input can generate zero, one, or multiple outputs, which cannot be achieved with traditional neural networks. Video processing and AI perception necessitate streaming processing as opposed to batch methods.
💡 OpenCV 4.0 introduced the Graph API, which allows the creation of sequences of image processing operations in the form of a graph. On the other hand, MediaPipe supports operations on diverse data types and offers native support for streaming time-series data, making it more suitable for analyzing audio and sensor data.
Is it genuinely Real-Time? 🤯
It’s almost near to real-time. The inference latency & performance might vary as per different device specs.
But yes, MediaPipe is designed to provide real-time performance. It offers efficient and optimized processing pipelines that enable real-time analysis and inference on various multimedia inputs, including video, audio, and sensor data. MediaPipe incorporates techniques such as parallel processing, hardware acceleration, and optimized algorithms to ensure fast and responsive performance, making it suitable for applications that require real-time processing capabilities.
References 📌
Here are the links to some of the best resources to learn more about MediaPipe:
MediaPipe GitHub repository → 🔗 link
MediaPipe Object Detection CodePen demo (by Jen Person) → 🔗 link
Google AI Blogs → 🔗 link
Intro to MediaPipe by LearnOpenCV → 🔗 link
Sign Language detection by Sicara → 🔗 link
MediaPipe for dummies by AssemblyAI → 🔗 link
MediaPipe official research paper (Arxiv, 2020) → 🔗 link
Conclusion 🚀
MediaPipe offers a versatile framework for live and streaming media, enabling the development of customizable machine learning solutions which can be ideal for creating computer vision pipelines and complex applications. That concludes our discussion for now! I hope you found it informative. I am grateful to my mentor(s) for providing me with this opportunity, and I will do my best to make the most of it. To stay updated on my progress, I will be posting bi-weekly updates on my blog. I welcome suggestions and feedback, so please feel free to reach out to me on Twitter or LinkedIn. Stay tuned for more exciting blog posts! 😄

