

Mastering the Art of AI Research
Nobody actually teaches you how to do this. You get handed a problem, sometimes by an advisor, sometimes by whatever a frontier lab happened to publish last quarter, and you’re expected to produce something nobody has produced before. Since there’s no syllabus for that, most people reverse engineer the job from whatever they can observe from the outside, namely papers, conference talks, threads explaining last week’s results before you’ve even read the paper. The trouble is that this teaches you to look like a researcher rather than to be one.
Doing the actual work is a stack of smaller, learnable skills, and almost nobody names them out loud, which is part of why they feel mysterious. This piece tries to name a few of them. It draws on people who have spent real time figuring this out, in machine learning and outside it, and the hope is that by the end it reads less like advice and more like a description of how the people who are good at this actually spend their days.
Choosing a problem worth your time
The important thing is not to stop questioning.
Richard Hamming had a habit at Bell Labs that made him a little unpopular at lunch. He would ask whoever was sitting near him what the important problems in their field were, and then ask why they weren’t working on them. People started finding other tables.
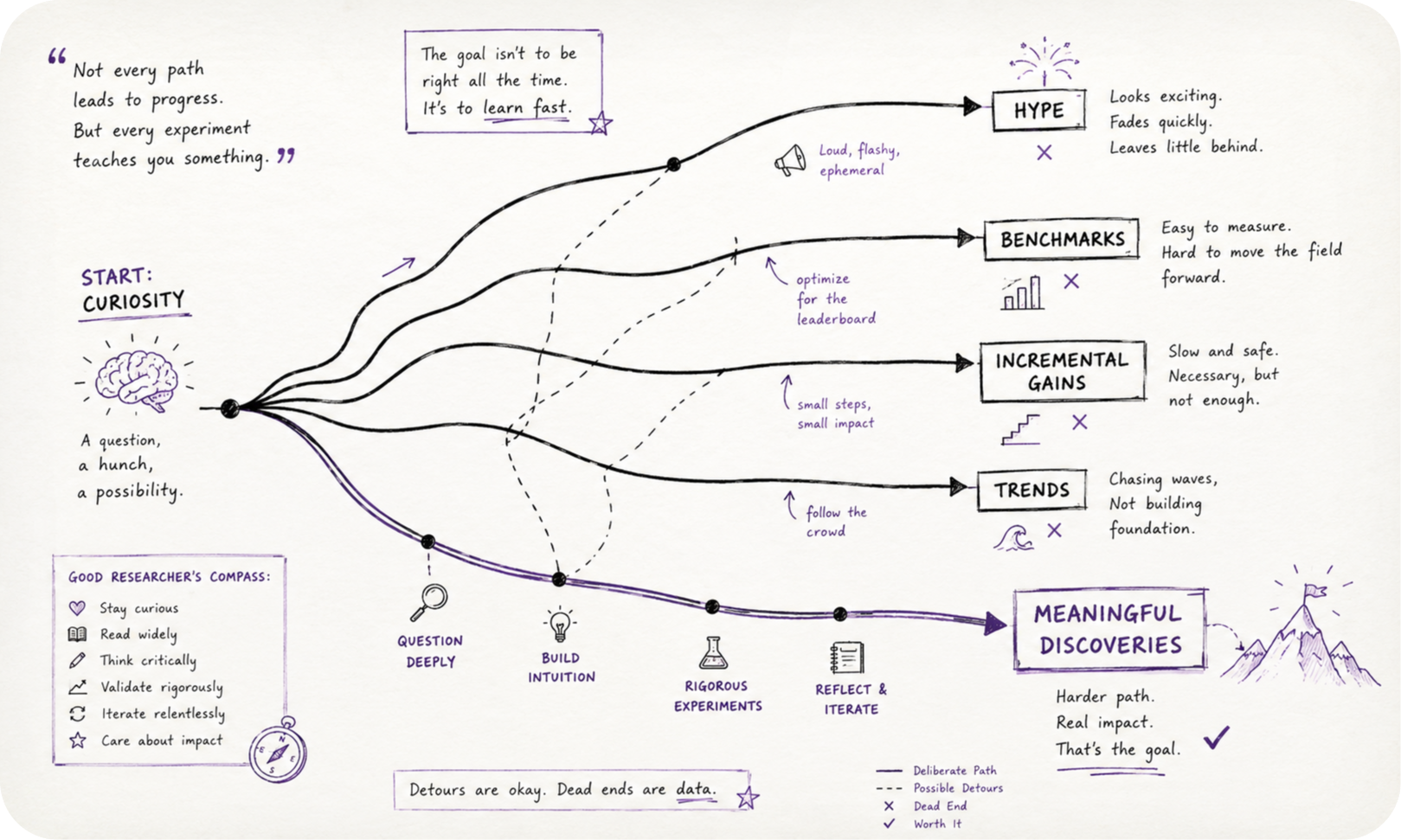
The question stings because most of us don’t have a real answer. We don’t choose our problems so much as absorb them, from an advisor’s interests, from a paper everyone is quote tweeting this week, from whatever direction a well funded lab announced it cared about. The trouble with an absorbed problem is that you inherit the conclusion without the reasoning behind it. You know that some lab is excited about a direction, but not why, not what result would make them double down, not what would make them quietly abandon it. When they pivot, you find out months later, usually from someone else’s recap. And if the problem was already fashionable when you picked it up, you’re competing against several thousand people who started earlier and have more compute.
John Schulman’s notes on doing machine learning research describe two different ways of finding something to work on.[1] The other starts from an outcome you actually want to exist, something you care about for reasons that have nothing to do with what’s trending, and works backward to the experiments that would get you there. He argues for the second mode, and I suspect the real benefit is that it manufactures originality as a side effect. A goal you actually care about drags you into territory no survey paper has mapped yet, because nobody else cared enough to go looking.
There’s a related trap specific to this moment in the field, i.e., mistaking the surface for the substance. AI moves quickly, but the underlying ideas have barely changed in decades. If you’re building a career rather than chasing a good quarter, you’re better served going back to fundamentals than getting clever about this year’s vocabulary. Know what cross entropy actually measures, and compute it by hand for a small distribution instead of just calling a loss function. Understand singular value decomposition well enough to picture it happening, not just well enough to call a library function. Skip the specific framing of reinforcement learning for coding and learn why policy gradients work, and why they’ve stayed useful for forty years. Agent harnesses and context engineering are this year’s words for things. They’ll be replaced by next year’s words. The math underneath will not.
One more filter, before you commit to a direction. If the best plausible outcome of a project is a slightly higher number on an existing leaderboard, you probably haven’t gone deep enough. Benchmarks get built to measure existing capabilities, which means they’re bad, almost by construction, at noticing anything genuinely new. Jason Wei has made a related point — finding or building a dataset that actually exercises the capability you’re trying to demonstrate is itself a research skill, and a fairly recent one, since ten years ago there were fewer methods novel enough to need it. Nobody can hand you the right problem. What they can hand you is a way of recognizing when you’ve picked a shallow one.
There’s no shortcut to the part where you have to actually go looking, either. A reasonable starting move is simply to spend real time in the deep end of a subfield rather than the shallow end, reading the foundational work and running small experiments of your own, on the bet that the right problem tends to surface on its own once you’re far enough in the water.
Two ways of working
I want to borrow a distinction from the physicist Michael Nielsen, made originally about his own field but transferring to machine learning without much friction, since the underlying psychology of research doesn’t change much across disciplines. He splits researchers into two idealized styles, namely — the problem solver and the problem creator.[2] Nobody is purely one or the other, but most people lean hard in one direction without ever consciously choosing to.
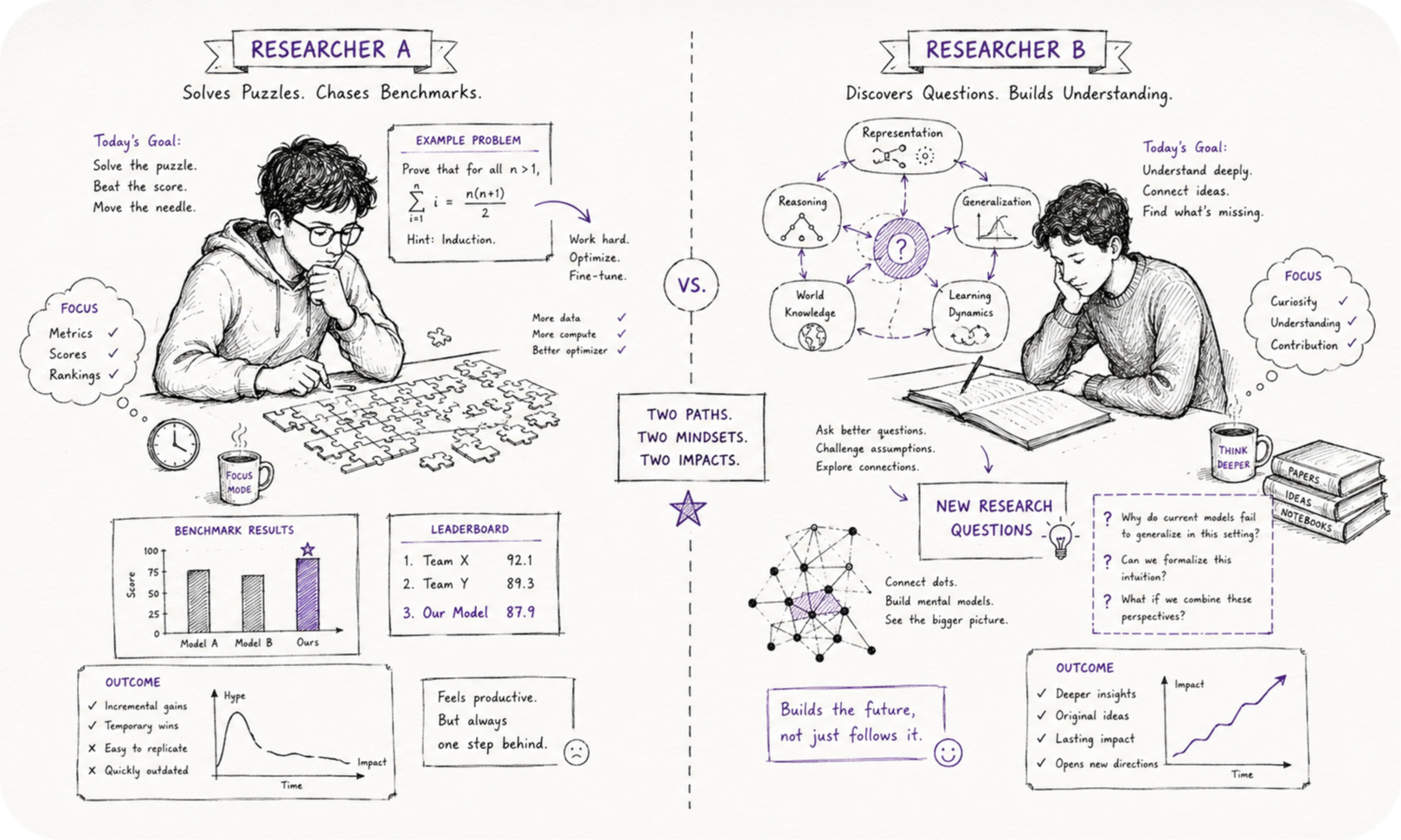
The problem solver looks for well posed, often well known problems and brings as much technical firepower as possible to bear on them. This style gets rewarded quickly and visibly, because everyone can recognize a hard problem solved cleanly, and difficulty is easy to signal on a CV. The problem creator does something rarer and harder to spot from the outside. They ask a question nobody had quite framed before, or notice a connection between two things that looked unrelated, often using methods that turn out to be technically simple once someone has pointed at them. The paper looks almost too easy in hindsight. That’s usually the tell that it was a creator’s paper rather than a solver’s.
Both styles can carry an entire career. The skills involved are nearly opposite, though. A problem solver mostly needs to get better at solving things. A problem creator needs to build a personal sense for what’s actually important, as distinct from what’s merely difficult, and the two get confused constantly because difficulty is so much easier to measure than importance.
That sense gets built through a habit of attention more than through any specific technique. Set aside real time, on a recurring basis, to think about what makes a research direction matter, separate from whatever you happen to be working on this week. Hamming called his version of this “Great Thoughts” time, hours set aside to talk with colleagues about nothing except what seemed most important, with the daily grind explicitly off the table. What looked promising five years ago and quietly died is at least as useful a question to sit with as what’s currently working, and most people never bother asking it.
Problem creators tend to do a more deliberate version of the same exercise, setting aside real time to survey an entire field at once rather than just the slice of it they happen to be working in this week, looking for the handful of questions everyone seems to be implicitly circling, and for unexpected links to fields that don’t normally talk to each other at all.
It helps to hold both an internal and an external reference point for what counts as important, and to be honest with yourself about which one is actually driving a given choice. The physicist Max Dresden once told a room full of young researchers not to chase a Nobel Prize, but to work on whatever they personally found interesting, on the grounds that aiming directly at external validation is a hollow way to spend a career. That’s good advice as far as it goes. But prizes, adoption, and citation counts usually do track something real, and ignoring that signal entirely is its own kind of arrogance. The honest position sits in the middle: let your curiosity choose the direction, then check it periodically against what the wider community has converged on, because working in total isolation rarely produces anything that ends up mattering to anyone but you.
Once you’re actively hunting for problems rather than waiting for one to land on your desk, a few moves repeat themselves. Sometimes an entire field agrees on what matters, and the competition for it is brutal. The better opening, when you can find it, is a problem that’s important but not yet appreciated, usually because it doesn’t look glamorous yet. The scanning tunneling microscope sat around as an obvious idea for years before anyone actually built one without serious funding behind it. Quantum computing exists as a field partly because Feynman and David Deutsch asked a specific, almost naive sounding question, what would a quantum mechanical computer actually be capable of, well before anyone had the tools to answer it.
There’s also the mess to consider. Steven Weinberg made a point worth remembering here, that some corners of a field stay confusing not because the ideas are hard but because nobody has found the right framing yet. General relativity texts were notoriously difficult to follow for decades, not because the physics was beyond anyone, but because the underlying definitions in differential geometry hadn’t fully migrated into a clean, modern form yet, so every textbook author was working with slightly wrong tools and the tensor calculus came out tangled as a result. The instinct, on finding a mess like that, is to go work somewhere cleaner. The better move, if you can stand the discomfort, is to lean in, because a genuine mess usually means a simplifying idea is still sitting there unclaimed.
And once you’re inside a problem, the underrated solver skills are worth naming too. Forward momentum matters more than most people admit, even when the clarity driving it is a little illusory. It’s almost always better to be doing something specific than nothing, as long as you build in regular checkpoints to reconsider whether the something is still the right something. The related mistake is holding too tightly to one formulation of a problem. If a related reformulation lets you actually move forward, that’s progress, even if it’s not the formulation you started with.
Training your taste
Research is what I’m doing when I don’t know what I’m doing.
Taste gets discussed like a gift you either have or don’t. In practice it behaves more like a muscle, and it responds to deliberate, slightly embarrassing practice. Before running an experiment, write down what you expect to see. Cover the results section of a paper you’re reading and guess the numbers from the method description alone. At the end of each month, mark down which new release you think will still matter in two years, and check yourself later. None of this feels like real research while you’re doing it. It’s exactly how every good predictive model gets trained, including the one sitting between your ears.
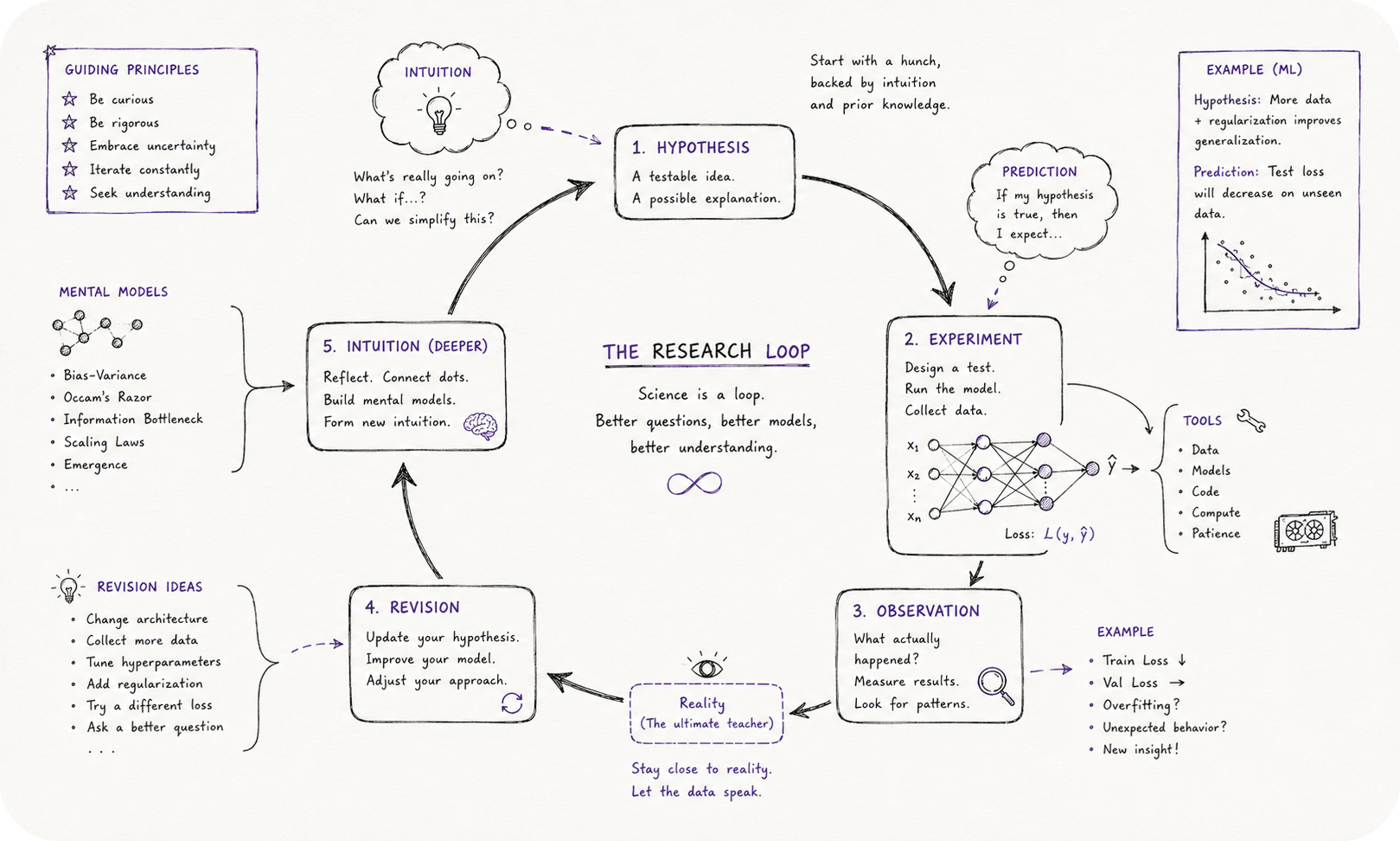
Where this taste actually comes from matters more than people give it credit for. A shared reading list produces shared conclusions. If your entire information diet is the trending page of arXiv plus whatever survives the filter of your group chat, you will reliably land on the same opinions as everyone else, at the same time, which makes those opinions worth roughly nothing in a competitive field. Reading something nobody else in your lab is reading isn’t a personality quirk. It’s one of the few genuinely renewable sources of a real edge.
Old material is badly underpriced by almost everyone under thirty in this field. Machine learning reruns its own history on a longer delay than people assume. Mixture of Experts shows up in the literature in 1991. LSTMs date to 1997. Backpropagation became standard practice in the mid 1980s. Rich Sutton needed something like a thousand words in 2019 to lay out the bitter lesson, and that short essay predicts the field’s trajectory better than most surveys ten times its length.[3] Claude Shannon gave a talk on creative thinking in 1952 where his opening move, on any hard problem, was to shrink it until it became nearly trivial, solve the trivial version, then reintroduce the difficulty one piece at a time.[4] That single move will carry you through more dead ends than any modern advice about productivity systems.
Range matters as much as depth past a certain point, maybe more. Interpretability borrows its best ideas from neuroscience without much shame about it. Designing a good evaluation is mechanism design wearing a different hat. A working mental model of how memory actually moves through a GPU will tell you which architecture papers are dead on arrival long before the benchmark numbers confirm it. And honest statistics might be the rarest skill in the field, since a lot of what passes for empirical rigor here is closer to vibes with error bars attached after the fact.
What to read, and how
Read the paper, not the thread summarizing it. This sounds obvious and almost nobody does it consistently, because the thread is faster and feels almost as informative. It isn’t. The appendix is where the inconvenient results get buried, and the limitations section is usually the single most honest paragraph in the whole document, written by people who know exactly where the work is thin and are obligated by convention to admit as much in three sentences near the end.
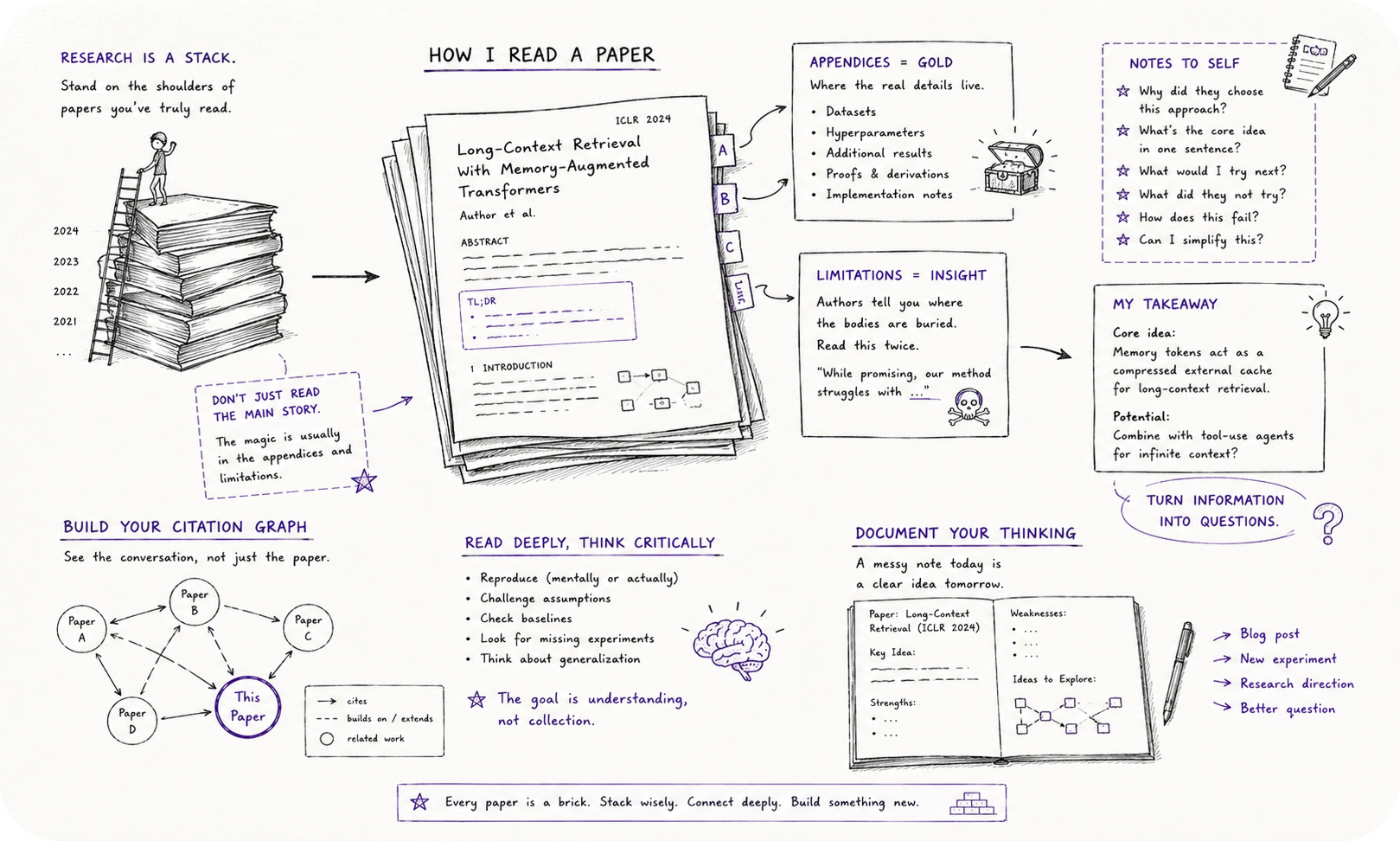
There’s also a depth versus breadth question most people get backward early on. The instinct is to feel like real competence requires some kind of completeness, that you need to have at least skimmed everything published in your subfield before you can claim to know it. In any given research area, though, the number of papers actually worth reading closely is small, usually well under twenty. You’re better off reading the ten most important papers in a field with real attention, working through the proofs and appendices, than skimming the top five hundred and retaining none of them well enough to use.
The way to stay current without losing the rest of your week is roughly two speed. Skim widely and constantly, just enough to track what people are thinking about and what’s considered settled versus open. Then pick a smaller number, a dozen or so papers a year, and read those properly, on the bet that they’re the ones that will still matter in five years. You’ll be wrong about which dozen sometimes. That’s fine. The discipline of choosing matters more than getting every choice exactly right.
Write everything down
The first principle is that you must not fool yourself—and you are the easiest person to fool.
Paul Graham has pointed out that an idea can feel completely finished right up until you try to put it into full sentences. The page exposes whatever your head was quietly papering over: the assumption you never tested, the step that doesn’t actually follow as cleanly as it felt like it did, two claims sitting side by side that mildly contradict each other. Feynman’s version of the same warning was that the easiest person in the world to fool is yourself, which makes writing the cheapest line of defense available to anyone.
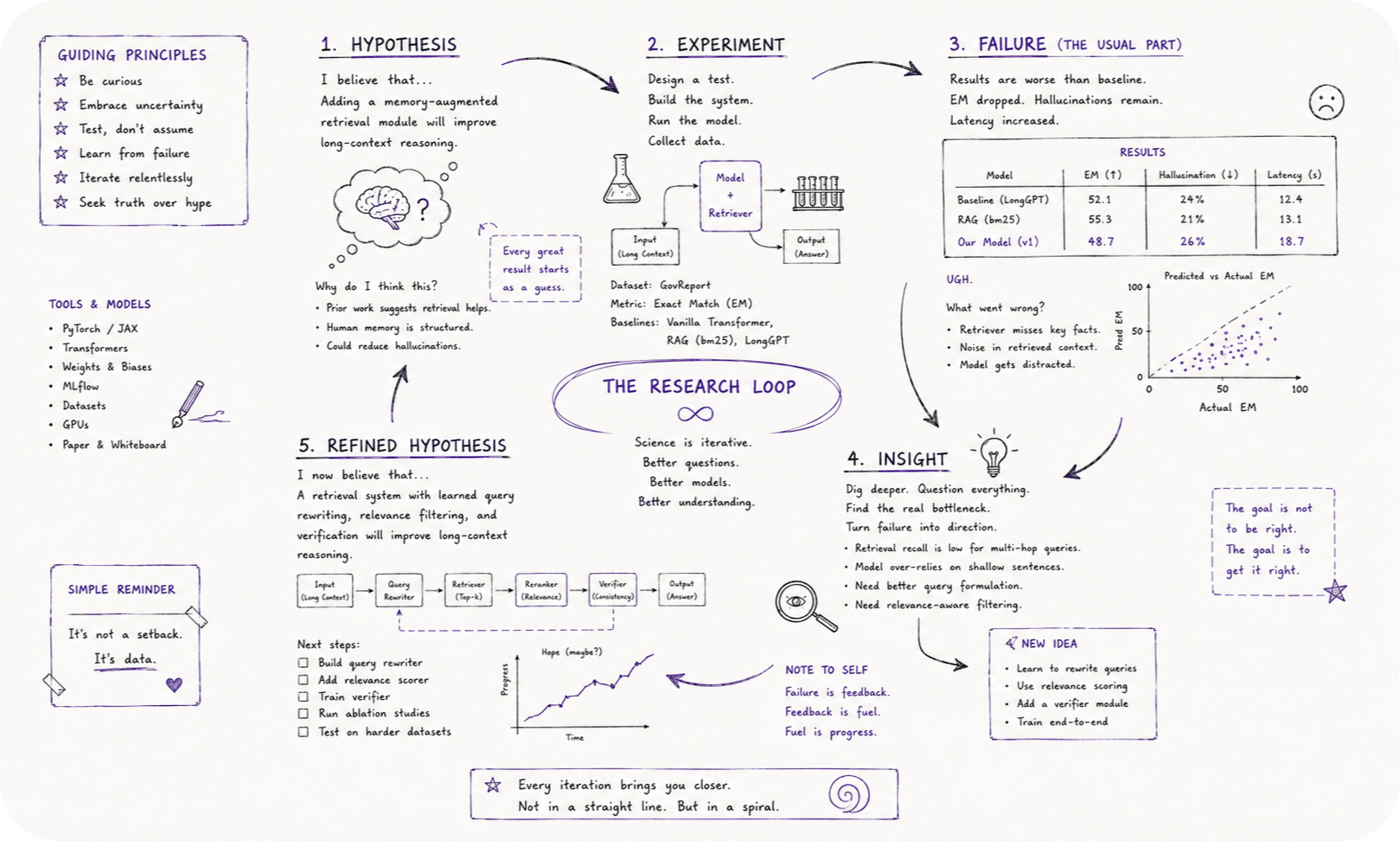
Darwin took this further and turned it into a procedure. Any observation that cut against his theory got written down immediately, on the spot, because he’d caught his own memory deleting inconvenient evidence faster than convenient evidence more than once. Your memory will do exactly the same thing to your failed experiments if you let it. Keep a running log, including hypothesis, setup, what you expected, what actually happened, and what you now believe as a result of the gap between the two. Reading back through last month’s entries is humbling in a way no reviewer’s comments quite manage, because you’re confronting your own pattern of being wrong rather than a stranger’s opinion of your work.
Some of that writing should eventually leave the private notebook. Chris Olah and Shan Carter’s essay on research debt argues that fields choke on ideas that technically exist somewhere but were never properly digested into something a newcomer can actually read, and that a genuinely clear explanation of an existing idea is a real contribution, not a lesser form of service work compared to a new result.[5] A lot of the people currently working in interpretability found their way in through readable blog posts rather than conference papers. A body of public writing also works as the strongest credential available to you, because unlike a line on a resume, it’s an almost unfakeable record of how you think when nobody is grading you.
Keep a beginner’s mind
There’s an old framing from Zen practice, that the beginner’s mind holds many possibilities, while the expert’s mind holds only a few. Inside AI research specifically, there’s a sharper version of this worth taking seriously. Experience earned in one era of the field can turn into a liability in the next one. Researchers who built their intuition before large scale training became standard practice sometimes keep reaching for methods that work cleanly at small scale and were never going to survive contact with scale, because that’s where their instincts formed, and instincts are sticky.
Part of why this field has moved as fast as it has is that almost nobody has had the chance to accumulate decades of entrenched priors yet. A striking number of the people making real technical decisions at the leading labs are under thirty five, and several of the people who shaped the systems most people now use day to day are under thirty. ChatGPT itself is barely four years old as I write this. Nobody has been doing this long enough to have a structural advantage from tenure alone, which is unusual for a serious technical field and probably won’t last.
The practical version of beginner’s mind is refusing to let an idea calcify just because it’s yours and it’s been yours for a while. Hold your models of how things work loosely enough that new evidence can actually move them. This is harder than it sounds, because the longer you’ve held a belief, the more identity gets wrapped around it, and updating starts to feel like losing an argument with yourself rather than learning something new.
None of this is really about youth, even though it’s tempting to read it that way. It’s about refusing to let an old idea harden into identity simply because it’s been sitting there a while, and staying willing to let go of it the moment the evidence stops cooperating. Ego is the thing standing in the way here far more often than experience itself.
Step away from the keyboard
Inspiration has an irritating habit of arriving exactly when you’ve stopped trying to summon it. The structure of the benzene ring, one of the foundational results in organic chemistry, reportedly came to its discoverer in a dream, a snake biting its own tail standing in for a ring nobody had pictured quite that way before. Ozempic’s active mechanism traces back to a hormone first isolated from the venom of the Gila monster, a desert lizard that eats only a handful of times a year, by a chain of reasoning nobody could have planned from a whiteboard.
The takeaway isn’t mystical. It’s that doing good research requires doing things other than research, deliberately and often.
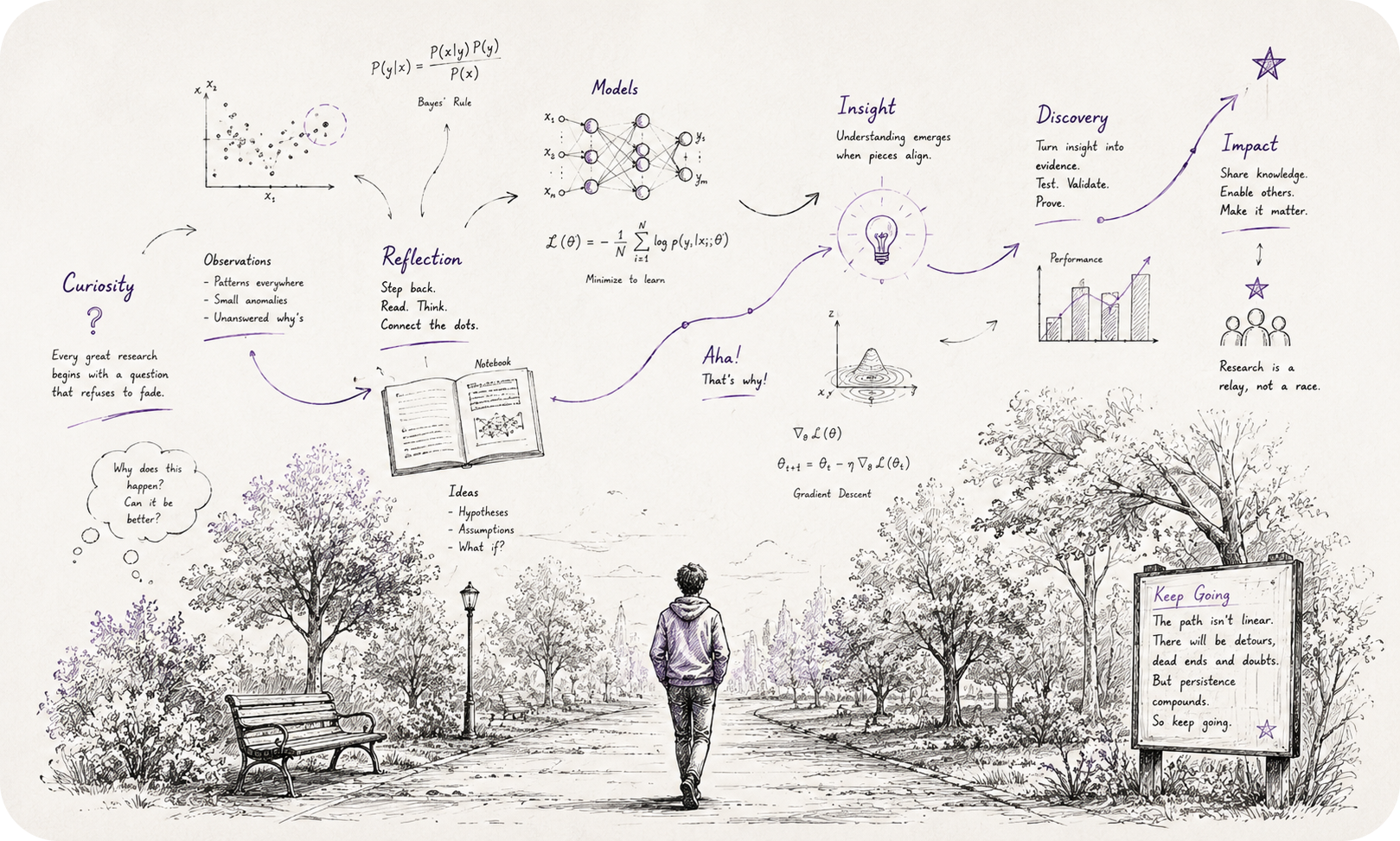
Most of the real “I think I see it now” moments I’ve had personally showed up away from a screen, usually on a walk. Darwin walked the same gravel path outside his house most days specifically to think. Tesla, Feynman, and Aristotle all left behind enough testimony about the value of walking that it stopped feeling like coincidence a while ago. You don’t need to be doing research at all to get something out of this. Everyone should probably walk more than they currently do.
Treat results with the same attitude either way
There’s a Zen image that maps onto experimental research more closely than it has any right to. On the days insight arrives, you sit. On the days it doesn’t, you also sit. Most days, for most researchers, insight does not arrive. The trait that actually predicts long term success is the willingness to keep putting in disciplined hours regardless, the same trait that separates a serious musician or athlete from someone who only shows up when they feel inspired.
Noam Shazeer’s paper introducing the SwiGLU activation closes, half jokingly, by declining to explain why the architecture works at all and crediting its success to nothing more rigorous than good fortune. It’s a useful attitude to borrow, not because the work itself was arbitrary, but because pretending you always know exactly why something worked is usually a sign you haven’t looked hard enough for the alternative explanation. A related, less comfortable habit is reading fewer papers than you think you need before attempting your own solution. The well worn path is to try something yourself, hit a wall, push at the wall yourself first, and only then go looking for what the literature already worked out. Reading everything up front, before attempting anything, tends to produce derivative work, because you’ve absorbed the field’s existing frame before you had a real chance to form your own.
When results actually come in, the healthiest response treats a positive and a negative result as close to equally informative, which is not how it feels in the moment. A failed experiment that rules something out isn’t a wasted week. It’s data, often more data than a single positive result hands you, since a string of failures usually narrows the hypothesis space faster than one success does. The flip side is harder to practice, i.e., be suspicious of results that feel too clean. Most surprisingly good results trace back to a bug rather than a real effect, a metric computed slightly wrong, a baseline that was quietly undertrained, an evaluation set that leaked into training somewhere upstream. Wanting your idea to work is healthy and normal. Believing it worked the first time the numbers look good is usually a mistake.
This connects to something Collin Raffel has pointed out, that plenty of ideas written off as bad ideas were actually fine ideas sitting behind a bug nobody caught in time. The modern deep learning stack is complicated enough that bugs hide in training, in inference, in the evaluation harness, or in the data pipeline, and a hidden bug produces a result that looks like a clean negative rather than an error. The discipline that catches this is close to paranoia. If a logged metric looks even slightly off from what you expected, you owe yourself an explanation before moving on, because the gap between expectation and reality is exactly where bugs like to hide. Log more than feels necessary. Understand all of it, not just the headline number.
Speed is most of the game
Luck favors the prepared mind.
A lot of the stories told about Alec Radford’s research output don’t actually involve a single flash of brilliance. They involve volume: more experiments run per day, more bad ideas discarded per week, an internal model of what would and wouldn’t work that updated faster than almost anyone else’s. Research speed, in the end, is mostly the speed at which you find out you were wrong about something.
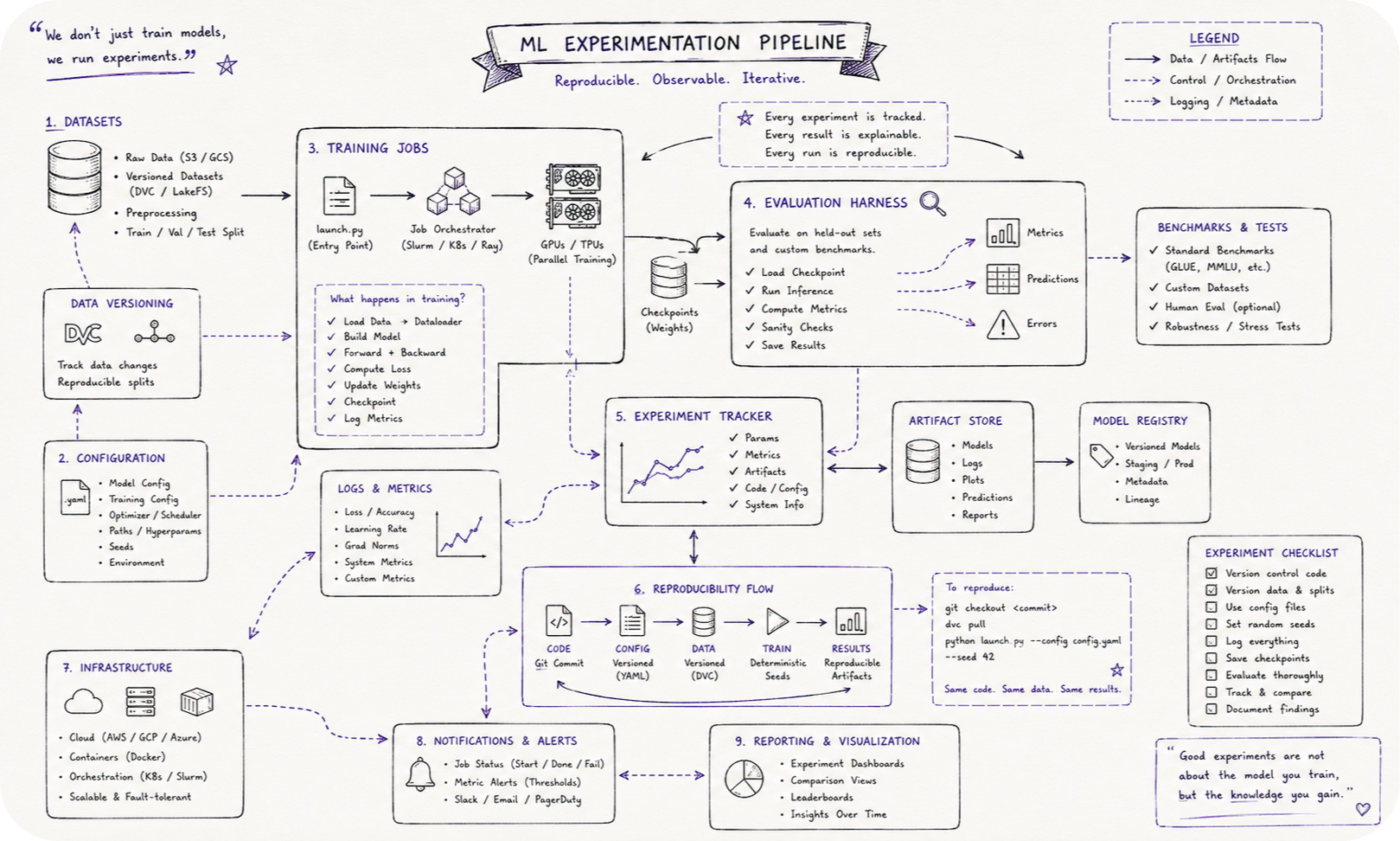
Which makes tooling a research activity in its own right rather than a support function sitting outside the real work. Launching a run should be one command. Plotting the result should be one more. Every experiment should be reproducible directly from its saved configuration, and comparing two runs should take seconds rather than an afternoon spent reconstructing what changed between them. One of the cheapest debugging habits around, borrowed from Andrej Karpathy’s well known recipe for training neural networks, is to overfit a single batch before scaling up to the full run. Thirty seconds of work catches a surprising fraction of bugs before they cost you a full day.
It’s worth retiring the idea, if you still hold it somewhere, that engineering sits one step below the actual research. At the frontier of the field those two jobs have basically merged. The person who can build the harness, the evaluation, and the data pipeline themselves is the one whose hypotheses actually get tested in a given week. Everyone else is stuck waiting in someone else’s queue.
There’s an unavoidable complication, which is that a lot of real deep learning work simply takes a long time no matter how good your tooling is. Training runs can stretch over weeks. Evaluating a single model on a single task can eat several days on its own. The instinct, especially once coding agents can babysit jobs without complaint, is to launch many experiments at once and let them all crawl forward in parallel. That helps to a point, but constant switching between a dozen half finished runs is a quietly expensive habit, because every switch costs you the mental state you’d built up about that specific run. Keller Jordan’s nanoGPT speedrun is worth studying for exactly this reason, as a demonstration of how much faster real learning happens when the loop itself gets compressed rather than merely parallelized.[6] And when something does need days to finish, the skill that pays off is holding enough state, in your head or in your notes, that you can pick the thread back up cleanly when the run finally lands a week later.
Coding agents cut both ways
Agents make you faster, and at the same time they make two specific problems worse, where you understand the basic details of your own system less well than you used to, and you context switch more often because spinning up a new experiment now costs almost nothing. A good researcher has to actively work against both effects, because neither one announces itself. You don’t feel less knowledgeable in the moment. You just are.
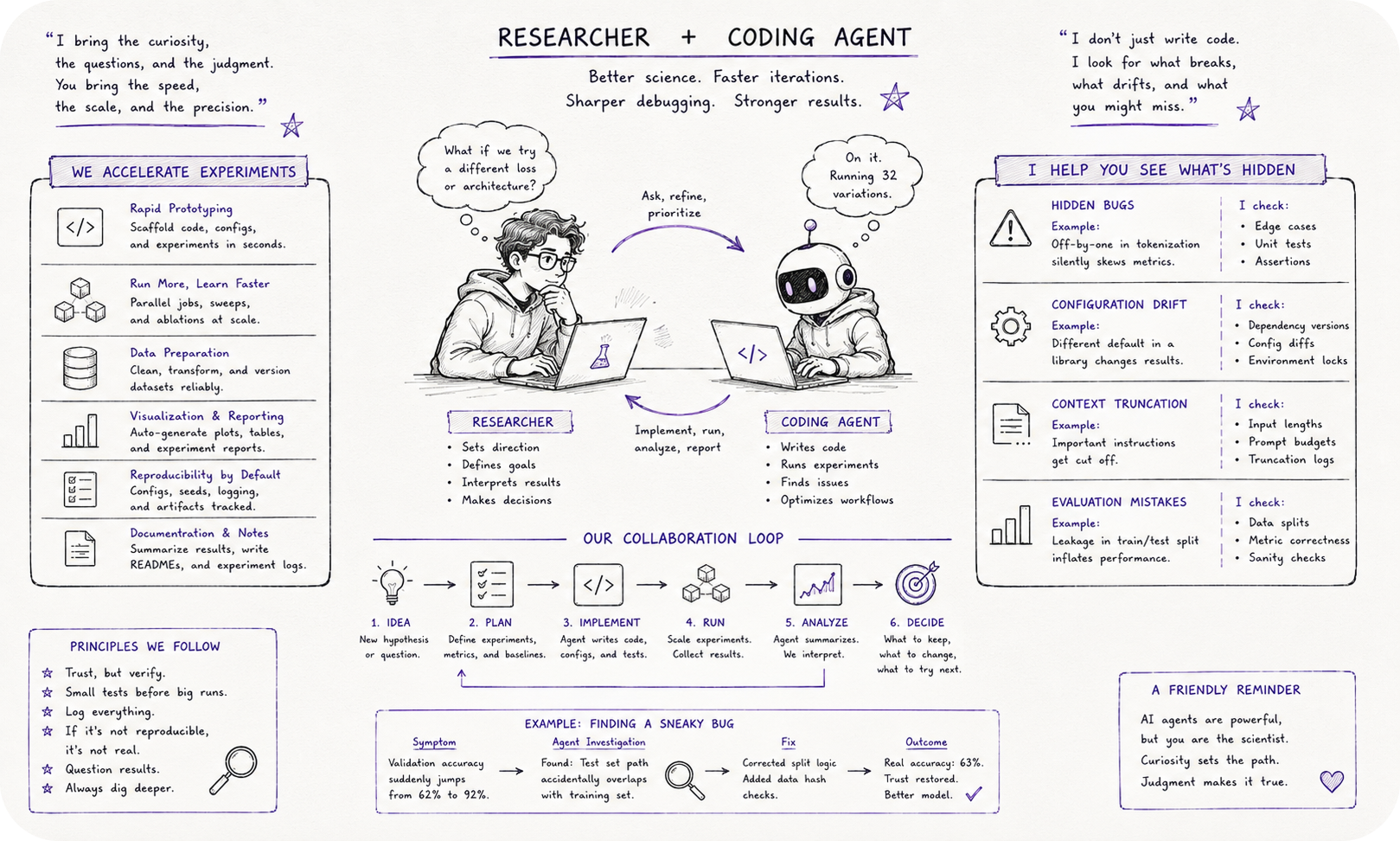
An agent can write your training script, launch it, babysit it overnight, and summarize the results by morning. It can also quietly truncate your system prompt after hitting a context limit it never mentioned, shorten your sequence lengths to get an evaluation finished in a reasonable window, or simply run the wrong configuration because you weren’t specific enough about which one you meant. From an engineering standpoint these are minor, easily patched mistakes. From a scientific standpoint they’re not minor at all, because a small unannounced change like a quietly truncated context window can shift the headline result of an entire experiment, and that kind of silent shift is exactly the failure mode that ends up baked into a paper’s conclusions without anyone noticing. There’s an old bit of cartographer’s shorthand worth borrowing for moments like this, the warning scrawled at the edge of unmapped territory: beware dragons. The unexamined corner of your own pipeline is usually exactly where they’re hiding.
This is genuinely hard to guard against. Outsourcing your understanding to whatever system did the work is faster in the moment, almost every time, which is exactly why it’s tempting. But real science requires understanding the whole pipeline well enough to know whether a given observation is actually true, independent of who or what wrote the code that produced it. There’s no shortcut around this part. If you didn’t write a given piece of the system, you still need to be able to explain what it’s doing before you trust what it tells you.
Look at your actual outputs
A descending loss curve tells you that optimization is happening. It’s reassurance, not analysis. Every real experiment throws off far more information than most people bother to consume: transcripts, individual failure cases, the strange long tail of examples that don’t fit the pattern you expected. Almost all of it dies unread in a logs directory, which is wasteful, because it’s usually the cheapest signal you have.

Karpathy’s training recipe deliberately starts before any training code gets written, with hours spent just looking at the raw data by hand. Most machine learning bugs live quietly inside the data, and they fail silently. Nothing crashes. You simply end up with a mediocre model and a confident, wrong theory about why, because the actual cause never announced itself.
Andrew Ng has taught a version of the same move for well over a decade, because nothing else has replaced it. Pull a hundred failure cases, read every one, sort them into rough piles by hand, and go attack whichever pile is biggest. It works on trained models, and it works on the evaluations you build to measure them, since a benchmark you’ve never personally read transcripts from is a benchmark you don’t actually understand, regardless of how many papers cite it. One transcript of genuinely strange model behavior will usually teach you more than the next decimal point of accuracy ever will.
Grunt work is the job, not a tax on it
There’s another piece of Zen phrasing that fits research uncomfortably well. Before enlightenment, chop wood, carry water. After enlightenment, chop wood, carry water. The unglamorous tasks don’t go away once you get good at this. Karpathy hand labeled a meaningful chunk of ImageNet himself. The people who built SWE-bench, well before most of the field had caught up to why an evaluation like that would matter, spent hundreds of hours manually filtering raw GitHub data down into a small, tractable set of issues actually usable for evaluation.
Look closely at the careers of researchers who eventually did something people remember, and almost all of them spent a long stretch working in relative obscurity first, on tasks that weren’t interesting enough to mention at dinner. Get comfortable with that stretch, because it doesn’t skip you just because your idea happens to be good. If anything, the more ambitious and forward looking an idea is, the more grunt work it tends to demand before it’s even possible to evaluate properly. That difficulty is a feature of working ahead of the curve, not a sign you picked the wrong problem.
Wander before you specialize
Your first subfield is almost always an accident of timing rather than a considered choice, so it’s worth treating it that way.
Spend real, sustained time across a few different corners of the field before settling, including interpretability, evaluation design, reinforcement learning, the systems side of things. Somewhere in this field is a corner where whatever makes you specifically odd is an unfair advantage, and the only way to find it is to spend time in several places first. Nobody hands you that answer for free.
Once you do commit to an idea, run the cheapest possible version of it first and let most ideas die at that stage, before they’ve cost you real time. Tune your baselines until it genuinely hurts to keep tuning them, because the graveyard of this field is full of reported gains that quietly evaporated the moment someone properly tuned the baseline being compared against, and a peer reviewer is the worst possible person to be the one who discovers that about your work. Once something does show a real effect, ablate it down until you know which specific component is actually carrying the result. Usually it’s exactly one component, and usually it’s not the one that ends up in the paper’s title, since the title gets written for narrative reasons after the fact.
There’s a specific, slightly sneaky version of this wandering worth calling out on its own. When two fields collide and a new area opens up between them, researchers from both sides tend to show up in large numbers, and almost none of them put in the work to actually learn the other field in any real depth. They borrow vocabulary, skim the relevant background, and move on. The handful of people who do sit down and properly learn both sides tend to produce results that look disproportionate next to the effort involved, not because they’re smarter, but because almost nobody else paid the entry price. Nobody can be better than everybody at everything, but almost anybody can be better than everybody at one specific thing, for one specific stretch of time, if the combination is chosen carefully. That’s the actual prize for wandering before you specialize.
Breadth also works as insurance against a risk that’s easy to underrate from inside a hot subfield. Every subfield saturates eventually, almost always right after it peaks on social media, and the researchers who keep producing good work through that transition are reliably the ones who already had footing in the neighboring territory before the saturation hit.
Find your people, and be generous first
Hamming noticed a pattern among his colleagues worth remembering. The ones who kept their office door closed tended to get more individual work done in a given year. The ones who kept it open were more often the ones who did the work that actually mattered, because the constant interruptions carried real information about what the people around them needed. Your open door, these days, is probably your inbox. It’s worth keeping it that way even when it’s inconvenient.
Generosity compounds in research in a way that doesn’t show up anywhere on a CV directly. Replicate someone else’s result and publish what you actually found, including the parts that didn’t match. Release the small tool you built only for yourself. Explain something genuinely difficult in language a newcomer could follow. None of this pays off on the timeline you’d expect. It pays off sideways, months or years later, as a collaboration nobody could have predicted, a citation from someone you never met, or a role that didn’t exist until someone remembered your name for it.
Float half formed ideas in public before they’re finished, too, because being visibly wrong in a conversation or a short post is far cheaper than being wrong in a published paper, and the correction tends to arrive faster as well. The single most valuable kind of collaborator is the one willing to tell you an idea is weak before you’ve sunk three months into it. That kind of honesty can’t really be hired. It has to be earned, usually by being that same kind of honest with other people first.
Building an environment where this exchange happens at all is itself a research skill, one that gets underrated, especially by students who assume the environment is fixed and they just have to adapt to it. Anyone can start a reading group, set up a regular seminar, or build a space where half formed ideas get a fair hearing instead of silence. These changes stick around far longer than the effort it took to start them, because institutions remember a working seminar series long after whoever started it has moved on, and each improvement you make to your own environment tends to raise your standing with the people already inside it.
People consistently underestimate how much an environment shapes effectiveness, and academic and lab settings are full of short-term pressures that have nothing to do with doing good research — teaching loads, letters of recommendation, referee reports, committee work, the general churn of departmental politics. None of that goes away on its own, but the lever for changing it is closer to hand than it usually feels. I’ve known undergraduates whose accumulated small contributions to a department, a reading group here, a useful internal tool there, gave them a kind of standing with senior faculty that took other people a full career to earn. The leverage compounds faster than the effort required to build it, which is a rare enough deal that it’s worth taking seriously.
A flower doesn’t compete with the flower next to it. It just blooms, on its own schedule, for its own reasons.
One more thing worth saying plainly. Comparing your output to other people’s, in a field this visible, is a fast way to make yourself miserable for no useful reason, and a lot of it has nothing to do with merit. Some people get lucky, and academic review in particular is neither especially consistent nor especially fair. When someone else publishes a result you admire, the more useful question isn’t why didn’t I think of that, but something closer to was I actually working at the depth required to have found this myself. If the honest answer is yes, your process is fine. You were doing something else at the time, and that’s not a failure. If the honest answer is no, that’s useful information too, pointed at where to go deeper rather than at how you should feel about it.
Have a vision
One never notices what has been done; one can only see what remains to be done.
Effective researchers tend to carry some version of a vision around with them, a rough answer to questions like what kind of researcher they’re trying to become, which areas actually interest them and why, and how the next few years of work fit into that picture. Most people never write any of this down, which is part of why it stays vague enough to be useless.
A good vision holds long-term values alongside short-term realities at the same time. If you’re in a temporary position and need a job in a year, pouring every spare hour into a subject with no visible output yet is probably the wrong call, however interesting that subject is. The balance shifts as your circumstances change, and a vision that never gets revised isn’t a vision so much as a habit you’ve stopped examining.
It’s worth occasionally aiming at something bigger than the next paper, something genuinely exciting enough that it changes how you think about an ordinary Tuesday. This matters more in the abstract corners of the field, where it takes real effort to build an emotional connection to the work at all. Without that connection, it’s easy to drift into a competent, slightly numb version of research, technically fine, never quite alive. A goal large enough to be a little frightening tends to fix that, even if the goal itself eventually changes shape, which it will, and should.
None of this arrives in one sitting, either. A vision worth having gets built the same way everything else on this list does, through repeated, deliberate attention rather than a single weekend of reflection. Put time aside for it specifically, the way you’d put time aside for reading or for an experiment, and expect the first few drafts of it to be wrong in ways that only become obvious in hindsight.
Working on problems that actually matter
If you do not work on an important problem, it’s unlikely you’ll do important work.
Most people who never end up tackling an important problem aren’t held back by talent. Three more ordinary things get in the way instead.
The first is simply running out of room to grow before you’ve developed enough to recognize an important problem when you see one, let alone solve it. If your development effectively stopped around the time of your first paper, the rest of your career tends to circle that same level of ambition indefinitely, because nothing forces further growth once the credentialing pressure eases off.
The second is the treadmill of small, fundable, publishable problems, which is genuinely hard to step off voluntarily once you’re on it, because the short term incentives for staying on it are real. Grants, jobs, and the steady approval of your immediate community all reward a fast, dependable stream of modest results. The honest path through this isn’t refusing the treadmill outright. It’s starting on smaller, tractable problems early, building a track record and real skill at the same time, and letting the size of the problems you take on grow alongside your own development. Even once you’ve earned the standing to chase something genuinely important, it’s worth continuing to publish smaller things along the way. Andrew Wiles kept working on and publishing other results, at a reduced pace, throughout the years he spent on Fermat’s Last Theorem, largely to stay connected to a community he would have badly needed had the larger bet gone wrong.
The third reason sits closer to fear than to laziness, and it’s the one people admit to least. Imagine spending a decade on a problem and simply failing. That prospect alone keeps a lot of capable people away from the biggest questions in their field indefinitely. Andrei Kolmogorov had a specific trick for defusing it. Instead of betting everything on solving the problem outright, he’d announce a lecture series on material related to it, then turn the notes into a book. The lecture series itself was guaranteed to produce something of value regardless of whether the underlying problem ever got solved, which lowered the psychological stakes enough that he could commit his attention to the harder question underneath. Feynman described a related private trick, convincing himself, often without much real evidence, that he had some unusual private insight into a problem nobody else had quite spotted. He admitted the belief was usually wrong, or at best mildly original. The fiction was useful anyway, because it generated enough forward momentum to actually get started, and getting started turned out to be most of the battle.
There’s a related trap that runs in the opposite direction, less talked about because it looks responsible from the outside. Some people spend years quietly developing, reading, taking courses, building skills, without ever putting a contribution out into the world, and the academic system eventually notices and shows them the door, because self-development with no output isn’t actually research, however much it resembles it from the inside. The healthier framing treats publishing, even something modest, as a standing obligation to the community you’re part of, rather than a distraction from the real work waiting somewhere down the road. A few solid, unglamorous results a year keep you inside the conversation while the bigger thing matures quietly in the background.
Commitment to a genuinely hard problem tends to happen gradually rather than as one decision. You prepare a single talk about it. If that goes well and you learn something from preparing it, you prepare a few more. Eventually you’re writing a review, then making a real contribution, having built up the insight piece by piece instead of betting it all up front.
There’s a failure mode at the opposite extreme worth naming too, refusing to work on anything except problems that are both difficult and important. Early in a career this looks like a novice pole vaulter who insists on starting the bar at five meters, who then never clears it and never learns anything from the attempts because the gap between attempt and success never narrows. Later in a career it looks different but lands in a similar place. An experienced researcher who only attacks the hardest, most important questions eventually stops contributing in any visible way, loses the simple habit of finishing things, and often loses morale along with it, since morale depends more on regular small wins than most people expect. The fix in both cases is the same unglamorous balance. Schedule real time for the big swing, but keep enough smaller, achievable work in rotation that you stay connected to your own sense of competence.
Take ownership of your circumstances
Men are disturbed not by the things which happen, but by their opinions about the things.
There’s an old story about someone asking a McDonald’s executive what actually gave the company its edge over every other fast food chain. The answer was something almost insultingly simple: they kept their restaurants, and the area immediately around them, extremely clean, every single time, everywhere. When the interviewer pushed back, pointing out that any competitor could do the exact same thing, the answer came back unchanged. Anyone could. Only McDonald’s did. The edge was never a secret. It was just unusually consistent execution of something boring.
Most of us, most of the time, find it easier to manage the story we tell about our problems than to actually fix them, and there are a few specific, well worn ways of doing that.
- The first is blaming circumstances. Not enough grant money, too much teaching, a supervisor who isn’t pulling their weight, students who aren’t strong enough, no time left over for research after everything else gets handled. Some of these complaints are completely fair. The trouble is that voicing them, on its own, quietly relieves you of the responsibility to do anything differently, because if the problem really is entirely external, there’s nothing left for you to act on. That’s a comfortable place to stand, and it’s also a dead end.
- The second is displacement. Plenty of activity feels productive and earns real, immediate approval from other people, responding fast to anything labeled urgent, attending every meeting, keeping every inbox at zero, without actually moving the research forward at all. It’s the easiest trap to fall into precisely because it doesn’t look like avoidance from the inside. It looks like being responsible.
- The third is turning the difficulty inward instead of outward, getting caught in a private loop of worry and self-criticism instead of doing anything about the actual problem. Winston Churchill described something like this as a black dog that followed him during the lower periods of his political career. The honest response to a real setback isn’t to spiral on it or to pretend it isn’t happening. It’s closer to admitting plainly that things are going badly, writing down what the actual problems are, and working through them one at a time without letting the worry itself become the main event.
A smaller, specific version of all three shows up constantly in collaborations: a disagreement with a colleague that everyone quietly hopes will resolve itself if nobody mentions it. It almost never does. The uncomfortable conversation, had early and in good faith, is reliably cheaper than the slow motion version that happens by avoiding it.
There isn’t a shortcut to building this kind of ownership either, but a couple of things help. Deliberately spending time with examples of people who took responsibility for difficult situations, whether through direct contact, biographies, or just paying closer attention to how the people around you actually handle setbacks, tends to rub off given enough exposure. So does periodically reminding yourself, in plain terms, what reactivity actually costs against what proactivity actually buys, since the calculation is easy to forget exactly when you need it most, which is usually in the middle of whatever is currently going wrong.
None of these patterns make anyone a worse person than anyone else. They’re just easier in the short run than the alternative, which is deciding that whatever isn’t working in your research life is, in the end, yours to do something about.
Keep the rest of your life in order
Excellence is an art won by training and habituation.
Research doesn’t happen apart from the rest of a life, however much it sometimes feels like it should. The whole enterprise rests on actually wanting to do it, at least some of the time, with real enthusiasm rather than obligation. Aristotle’s old line that we are what we repeatedly do holds up well here. Whatever habits you build around the work are, eventually, the work.
Wanting to do research isn’t sufficient on its own, either. Sleep, physical health, real relationships, and time that has nothing to do with work all need to actually be in order, not just acknowledged as important in the abstract. Neglecting them doesn’t only make the rest of your life worse, which would be bad enough on its own. It tends to make the research itself worse too, on a timescale longer than the one you’re optimizing for in the moment. A multi year project that consumes someone’s health and relationships in its final stretch often takes longer to finish, not shorter, than it would have if the person involved had kept their life functioning normally throughout. The short term gain from cutting everything else away is usually smaller than it looks, and it tends to get paid back with interest later.
I’ve had more trouble with myself than any other man I’ve ever met.
Wayne Bennett, one of the most successful coaches in the history of rugby league, made that admission without much ceremony, and it’s worth sitting with, because self-discipline gets treated as a simple matter of willpower far more often than the evidence actually supports.
Self-discipline rests on a few specific, somewhat mundane factors rather than pure willpower. The first is real clarity about what you’re trying to achieve and why, since most procrastination traces back to a foggy goal rather than a weak character. The second is your social environment, since researchers operate under far less external accountability than, say, professional athletes do, and a few well chosen collaborators or a regular mentoring relationship can substitute for the coach nobody assigned you. The third is a specific, slightly uncomfortable kind of honesty with yourself about how your time actually goes, as opposed to how you assume it goes. There’s a story about a researcher who tracked his working hours with a stopwatch out of plain curiosity, and discovered that after subtracting meetings, email, and the dozen small interruptions filling a normal day, he was averaging something like thirty minutes of real research per day. Most people would be uncomfortable running that experiment on themselves. That discomfort is exactly why it’s worth running.
The long game
The best way to have a good idea is to have a lot of ideas.
Pasteur is usually credited with the line that luck favors the prepared mind, and Hamming built an entire career philosophy on the same idea, that knowledge and productivity compound the way interest does. None of the daily habits described here look impressive in isolation. What you choose to read. Whether you actually write your failures down. How fast your experimental loop runs. Who you argue with on a regular basis. Each one looks small enough to skip on any given day.
Temperament ends up mattering more than raw talent in this calculation, since compounding rewards whoever keeps showing up rather than whoever happened to be sharpest in any single week. Staying curious beats staying clever, and staying meticulous beats staying merely inspired, across a career long enough for either one to matter. Give these small habits a few years and they produce careers that look, from the outside, like luck. They aren’t luck. They’re compounding, running quietly the entire time, on a timescale long enough that the connection between cause and effect stops being obvious to anyone watching from outside. The only real mistake available to you here is starting later than you needed to.
Whatever version of these habits you’re eventually going to adopt, the version of you a few years from now would clearly prefer that you started today instead.
Thanks for reading. Comments and corrections are welcome.
** P.S.: No tokens were harmed in writing this.
References
- [1]
John Schulman, “An Opinionated Guide to ML Research” (2017).
- [2]
Michael Nielsen, “Principles of Effective Research” (2004).
- [3]
Richard S. Sutton, “The Bitter Lesson” (2019).
- [4]
Claude Shannon, “Creative Thinking” (1952).
- [5]
Chris Olah and Shan Carter, “Research Debt” (2017).
- [6]
Keller Jordan, “modded-nanogpt” (nanoGPT speedrun) (2024).

